
関連記事: kaggleの記事
![]()
![]()
![]()
![]()
昨年末から始まった新型コロナウイルス感染症(COVID-19)感染者拡大の影響は、いまや世界中に広がっています。世界中のさまざまな業界の組織はCOVID-19の対策を支援しています。やはりデータサイエンティストや機械学習エンジニアもCOVID-19)の感染対策や治療方針の策定を支援しています。今回の記事は世界中のデータサイエンティストの競い合うプラットフォームKaggleからの「COVID19 Global Forecasting」について紹介したいと思います。
目次
1. COVID19 Global Forecastingの概要
___1.1 コンペの概要
___1.2 データセットの概要
2. モデル作成
___2.1 データの理解
___2.2 モデル
1. ASHRAE 消費エネルギー予測のコンペの概要
1.1 コンペの概要

概要
Kaggleでは今回の一連のコンペを通じて、感染者数の推移の予測によって世界保健機関(WHO)と全米科学・工学・医学アカデミー(NASEM)が抱える新型コロナウイルスに関連する疑問にも答えることです。
今回のKaggleのコンペでは、米ホワイトハウスらを通じて集められた感染者数などの各種関連データを使って、1ヶ月後の感染者数を予測するモデルを構築することになります。
賞金: -
期間: 2020/3/19 ~
第1週目のの評価:RMSLE
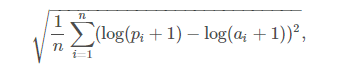
nは観測の総数です
piは予測値です
aiは実測値です
log(x)はxの自然対数です
最終スコアは、すべての列のRMSLEの平均です
第5週目の評価:Weighted Scaled Pinball Loss (WSPL)
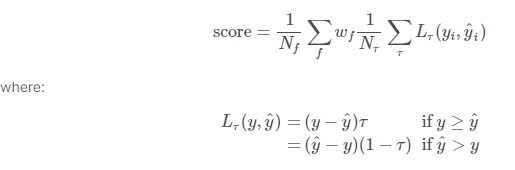
y は実測値です。
y^ は予測値です。
τ は分位予測です。 例 [0.05, 0.50, 0.95]
Nf は予測(f)日xターゲットの組み合わせの総数です
Nτ は予測する変位値の総数です
w は重み係数です
重みの計算:
確認済みのケース:log(population + 1)−1
死亡者数:10⋅log(population + 1)−1
1.2 データセットの概要(第5週目のコンペ)
submission.csv
– ForecastId_Quantile 予測参照番号
– TargetValue 予測値
test.csv
– ForecastId 予測参照番号
– County 国
– Province_State 地域
– Country_Region 国/地域
– Population 人口
– Weight 重量
– Date 日付
– Target 目標 (確認済み、死亡者数)
train.csv
– Id 参照番号
– County 国
– Province_State 地域
– Country_Region 国/地域
– Population 人口
– Weight 重量
– Date 日付
– Target 目標 (確認済み、死亡者数)
– TargetValue 目標値
2. モデル作成
2.1 データの理解
ライブラリのインストール
import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sea import plotly.express as px %matplotlib inline
全てのcsvファイルを読み込んで、データフレームを作成します。
train_df = pd.read_csv('../input/covid19-global-forecasting-week-5/train.csv')
test_df = pd.read_csv('../input/covid19-global-forecasting-week-5/test.csv')
train_df.head()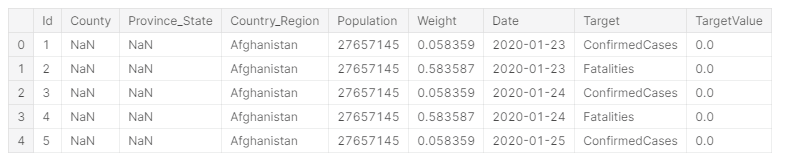
# データの確認
各国、毎日の確認済みと死亡者数のデータです。
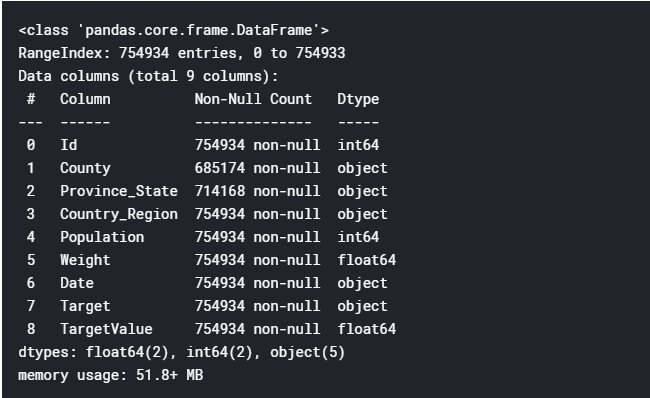
train_df.info()
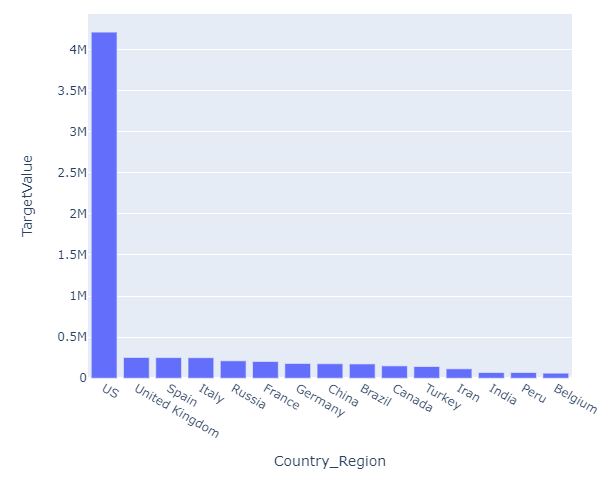
#トップ15国の可視化
実際にUSが多い事が最近のニュースからでもわかるようにデータもなっています。
l = train_df[['Country_Region','TargetValue']].groupby(['Country_Region'], as_index = False).sum().sort_values(by = 'TargetValue',ascending=False) w = pd.DataFrame(l) data1 = l.head(15) fig = px.bar(data1,x = 'Country_Region',y = 'TargetValue') fig.show()
#確認済みの累計
折れ線グラフは、4月のピークと5月の変動下降傾向になります。ロックダウンの対策などの効果だと考えられます。
last_date = train_df.Date.max()
df_countries = train_df[train_df['Date']==last_date]
df_countries = df_countries.groupby('Country_Region', as_index=False)['TargetValue'].sum()
df_countries = df_countries.nlargest(10,'TargetValue')
df_trend = train_df.groupby(['Date','Country_Region'], as_index=False)['TargetValue'].sum()
df_trend = df_trend.merge(df_countries, on='Country_Region')
df_trend.rename(columns={'Country_Region':'Country', 'TargetValue_x':'Cases'}, inplace=True)
px.line(df_trend, x='Date', y='Cases', color='Country')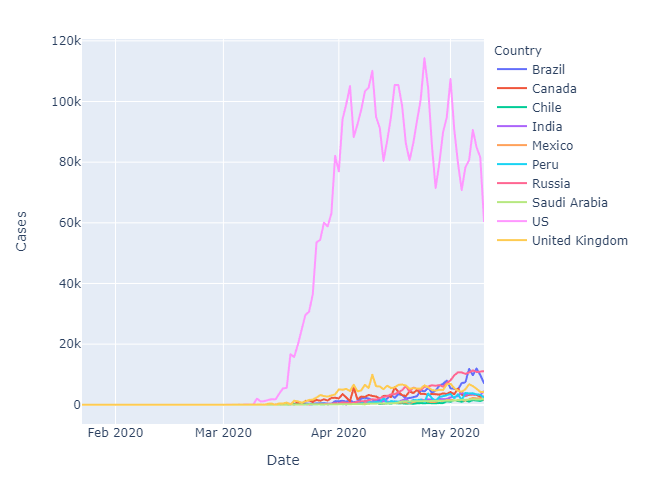
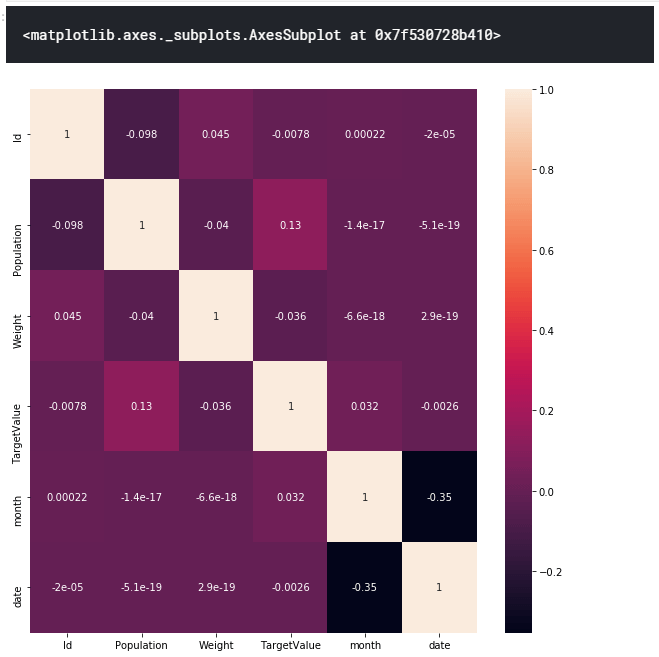
相関行列
相関の確認になります。Monthやdateもありますが、ほぼ疑似相関のものだと考えられます。
plt.figure(figsize =(10,10)) sea.heatmap(train_df.corr(),annot=True)
2.2 モデル
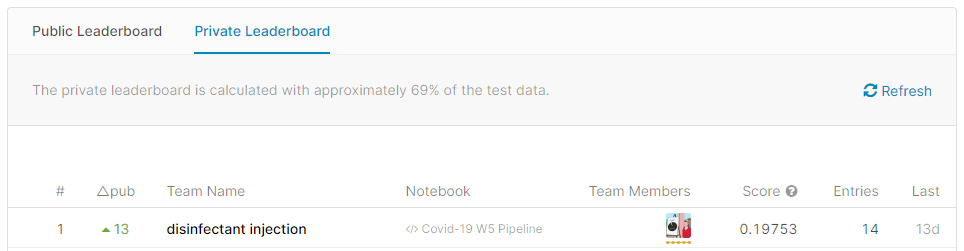
一位の解決方法を解説します。
![]()
![]()
特徴エンジニアリング
1) 日、週、月、年などの日付データを作成
2) 3、5、7の窓関数を適用する移動平均を作成していきます。
CAL_TYPE = {'County':'category', 'Province_State':'category', 'Country_Region':'category', 'Id': 'int32', \
'Population':'int64', 'Weight':'float32', 'Date':'str', 'Target':'str'}
CAL_DATA = ['id', 'week', 'day', 'month']
INPUT_DATA = ['target_before', 'target_3']
def make_dataset():
train_data = pd.read_csv(TRAIN_DATA_PATH, dtype=CAL_TYPE)
train_data['Date'] = pd.to_datetime(train_data['Date'])
train_data['week'] = train_data['Date'].dt.weekday
train_data['day'] = train_data['Date'].dt.day
train_data['month'] = train_data['Date'].dt.month
train_data['id'] = train_data['Country_Region'].str.cat(train_data['Province_State'], sep=' ', na_rep='')
train_data['id'] = train_data['id'].str.cat(train_data['County'], sep=' ', na_rep='')
train_data['id'] = train_data['id'].astype('category')
train_data['id'] = train_data['id'].cat.codes.astype('int16')
c_train_data = train_data[train_data['Target'] == 'ConfirmedCases']
f_train_data = train_data[train_data['Target'] == 'Fatalities']
c_train_data['target_before'] = c_train_data.groupby(by='id')['TargetValue'].shift(periods=1)
c_train_data['target_7'] = c_train_data.groupby(by='id')['target_before'].rolling(7).mean().reset_index(0, drop=True)
c_train_data['target_5'] = c_train_data.groupby(by='id')['target_before'].rolling(5).mean().reset_index(0, drop=True)
c_train_data['target_3'] = c_train_data.groupby(by='id')['target_before'].rolling(3).mean().reset_index(0, drop=True)
f_train_data['target_before'] = f_train_data.groupby(by='id')['TargetValue'].shift(periods=1)
f_train_data['target_7'] = f_train_data.groupby(by='id')['target_before'].rolling(7).mean().reset_index(0, drop=True)
f_train_data['target_5'] = f_train_data.groupby(by='id')['target_before'].rolling(5).mean().reset_index(0, drop=True)
f_train_data['target_3'] = f_train_data.groupby(by='id')['target_before'].rolling(3).mean().reset_index(0, drop=True)
# train_data.dropna(inplace=True)
# train_data.dropna(subset=['target_before'], inplace=True)
f_train_data.dropna(subset=['target_7'], inplace=True)
c_train_data.dropna(subset=['target_7'], inplace=True)
return c_train_data, f_train_data
def make_X(df, batch_size):
X = {'inputs': df[INPUT_DATA].to_numpy().reshape((batch_size, TARGET_DATE,3))}
for i, v in enumerate(CAL_DATA):
X[v] = df[[v]].to_numpy().reshape((batch_size, TARGET_DATE, 1))
return X
def make_X2(df):
X = {'inputs': df[INPUT_DATA].to_numpy()}
for i, v in enumerate(CAL_DATA):
X[v] = df[[v]].to_numpy()
return X
c_train_data, f_train_data = make_dataset()モデル作成
pinball_lossのモデル評価の設定
rmseのモデル評価の設定
モデルの設定 days=21, batch_size=2**14, epochs=200, lr=1e-3
完全畳み込みネットワーク FCN
割とシンプルなネットワークであることがわかります。特徴としては、バッチサイズが非常に大きいです。また移動平均の特徴量が大きなポイントだと考えられます。また損失関数を按分している点は、大きなメリットだと考えられます。
from datetime import datetime
from datetime import timedelta
import tensorflow.keras
from tensorflow.keras.models import Sequential, Model
from tensorflow.keras.layers import Dense, Input, GRU, Masking, Permute, Concatenate, BatchNormalization, Flatten, Embedding, TimeDistributed, Reshape, Dropout, Concatenate
from tensorflow.keras.callbacks import ModelCheckpoint
from tensorflow.keras.callbacks import EarlyStopping
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.regularizers import l2
from tensorflow.keras import backend as K
import tensorflow as tf
from tqdm import tqdm
import pandas as pd
import numpy as np
import gzip
import pickle
def pinball_loss(true, pred):
assert pred.shape[0]==true.shape[0]
tau = K.constant(np.array([0.05, 0.5, 0.95]))
loss1 = (true[:, 0:1] - pred) * tau
loss2 = (pred - true[:, 0:1]) * (1 - tau)
print(true[:, 1].shape, K.mean(loss1).shape, pred.shape)
print((true[:, 1] * K.mean(loss1, axis=1)).shape, loss1[pred <= true[:, 0:1]].shape)
loss1 = K.mean(true[:, 1] * K.mean(loss1[pred <= true[:, 0:1]]))/3
loss2 = K.mean(true[:, 1] * K.mean(loss2[pred > true[:, 0:1]]))/3
return (loss1 + loss2) / 2
def pinball_loss1(true, pred):
assert pred.shape[0]==true.shape[0]
loss1 = (true[:, 0:1] - pred) * 0.05
loss2 = (pred - true[:, 0:1]) * (1 - 0.05)
loss1 = K.clip(loss1, 0, K.max(loss1))
loss2 = K.clip(loss2, 0, K.max(loss2))
loss = loss1 + loss2
print(loss.shape, pred.shape)
loss = K.mean(true[:, 1:2] * loss)
return loss
def pinball_loss2(true, pred):
assert pred.shape[0]==true.shape[0]
loss1 = (true[:, 0] - pred)# * 0.5
loss2 = (pred - true[:, 0])# * (1 - 0.5)
loss1 = K.clip(loss1, 0, K.max(loss1))
loss2 = K.clip(loss2, 0, K.max(loss2))
loss = loss1 + loss2
loss = K.mean(true[:, 1] * loss)
return loss
def pinball_loss3(true, pred):
assert pred.shape[0]==true.shape[0]
loss1 = (true[:, 0:1] - pred) * 0.95
loss2 = (pred - true[:, 0:1]) * (1 - 0.95)
loss1 = K.clip(loss1, 0, K.max(loss1))
loss2 = K.clip(loss2, 0, K.max(loss2))
loss = loss1 + loss2
loss = K.mean(true[:, 1:2] * loss)
return loss
def rmse(true, pred):
loss1 = (true[:, 0:1] - pred)
loss2 = (pred - true[:, 0:1])
loss1_005 = loss1 * 0.05
loss1_005 = K.clip(loss1_005, 0, K.max(loss1_005))
loss2_005 = loss2 * 0.95
loss2_005 = K.clip(loss2_005, 0, K.max(loss2_005))
loss_005 = loss1_005 + loss2_005
loss1_05 = loss1 * 0.5
loss1_05 = K.clip(loss1_05, 0, K.max(loss1_05))
loss2_05 = loss2 * 0.5
loss2_05 = K.clip(loss2_05, 0, K.max(loss2_05))
loss_05 = loss1_05 + loss2_05
loss1_095 = loss1 * 0.95
loss1_095 = K.clip(loss1_095, 0, K.max(loss1_095))
loss2_095 = loss2 * 0.05
loss2_095 = K.clip(loss2_095, 0, K.max(loss2_095))
loss_095 = loss1_095 + loss2_095
loss = K.mean(true[:, 1:2] * ((loss_005 + loss_05 + loss_095) / 3))
# loss1 = K.clip(loss1, 0, K.max(loss1))
# loss2 = K.clip(loss2, 0, K.max(loss2))
return loss
# return K.mean(K.abs(true[:,0:1] - pred) * true[:, 1:2])
def simple_model(input_size, days=21, batch_size=2**14, epochs=200, lr=1e-3):
inputs = Input(shape=(input_size), name='inputs')
id_input = Input(shape=(1,), name='id')
wday_input = Input(shape=(1,), name='week')
day_input = Input(shape=(1,), name='day')
month_input = Input(shape=(1,), name='month')
id_emb = Flatten()(Embedding(3464, 3)(id_input))
wday_emb = Flatten()(Embedding(8, 1)(wday_input))
day_emb = Flatten()(Embedding(32, 3)(day_input))
month_emb = Flatten()(Embedding(13, 2)(month_input))
# x = Concatenate(-1)([inputs, id_emb, wday_emb, day_emb, month_emb])
x = Concatenate(-1)([inputs, id_emb, day_emb, month_emb])
x = Dense(128, activation='relu')(x)
x = BatchNormalization()(x)
x = Dropout(0.25)(x)
x = Dense(64, activation='relu')(x)
x = BatchNormalization()(x)
x = Dropout(0.25)(x)
x = Dense(32, activation='relu')(x)
outputs1 = Dense(1, activation='linear')(x)
# outputs2 = Dense(1, activation='linear')(x)
# outputs3 = Dense(1, activation='linear')(x)
# print(outputs.shape)
# outputs1 = outputs1 * 46197 - 10034
# outputs2 = outputs2 * 46197 - 10034
# outputs3 = outputs3 * 46197 - 10034
input_dic = {
'inputs': inputs, 'week': wday_input, 'month': month_input,
'day': day_input, 'id': id_input,
}
optimizer = Adam(lr=lr, name='adam')
model = Model(input_dic, outputs1, name='gru_network')
model.compile(optimizer=optimizer, loss=rmse)
# model.compile(optimizer=optimizer, loss=pinball_loss2)
# model.compile(optimizer=optimizer, loss=['mse', 'mse', 'mse'])
return model正規化
MinMaxScaler関数による前処理、最大値 1 、最小値 0 になります。
#Normalization from sklearn.preprocessing import MinMaxScaler min_max_scaler = MinMaxScaler() c_train_data_norm = c_train_data.copy()
モデル保存
cv19_predict_f.h5のモデルを保存します。
c_s_model = simple_model(2,)
model_path = './cv19_predict5.h5' # '{epoch:02d}-{val_loss:.4f}.h5'
cb_checkpoint = ModelCheckpoint(filepath=model_path, monitor='val_loss', verbose=1, save_best_only=True)
early_stopping = EarlyStopping(patience=10)
hist = c_s_model.fit(make_X2(c_train_data_norm), c_train_data_norm[['TargetValue', 'Weight']].values, batch_size=2**14, epochs=100, validation_split=0.2, callbacks=[cb_checkpoint, early_stopping], shuffle=True)
f_s_model = simple_model(2,)
model_path = './cv19_predict_f.h5' # '{epoch:02d}-{val_loss:.4f}.h5'
cb_checkpoint = ModelCheckpoint(filepath=model_path, monitor='val_loss', verbose=1, save_best_only=True)
early_stopping = EarlyStopping(patience=10)
hist = f_s_model.fit(make_X2(f_train_data_norm), [f_train_data_norm[['TargetValue', 'Weight']].values], batch_size=2**14, epochs=100, validation_split=0.2, callbacks=[cb_checkpoint, early_stopping])結果の結合
モデルを学習します。
tt = pd.merge(f_test_data[['ForecastId', 'County', 'Province_State', 'Country_Region',
'Population', 'Weight', 'Date', 'Target', 'week', 'day', 'month', 'id',]], f_train_data, how='outer', on=[ 'County', 'Province_State', 'Country_Region', 'Population', 'Weight', 'Date', 'Target', 'week', 'day', 'month', 'id'])
f_s_model.load_weights('./cv19_predict_f.h5')
# tt=tt.sort_values(by='Date')
f_result = test_seq(date_list, tt.sort_values(by=['id', 'Date']), f_s_model, min_max_