
(2019年7月27日の更新)
前回の記事は「モデル評価」を話しました。
今回の記事はグリッドサーチでのハイパーパラメータ最適化を解説します。
1)グリッドサーチ とは
グリッドサーチとは、モデルの精度を向上させるために用いられる手法です。全てのパラメータの組み合わせを試してみる方法のことです。機械学習モデルのハイパーパラメータを自動的に最適化してくれるというありがたい機能。例えば、SVMならCや、kernelやgammaとか
2)GridSearchCV関数の説明
Pythonの機械学習ライブラリscikit-learnにはモデルのハイパーパラメータを調整する方法としてGridSearchCVが用意されています。
class sklearn.model_selection.GridSearchCV(estimator, param_grid, scoring=None, n_jobs=None, iid=’warn’, refit=True, cv=’warn’, verbose=0, pre_dispatch=‘2*n_jobs’, error_score=’raise-deprecating’, return_train_score=False)
パラメータ名 説明
estimator : estimator object
チューニングを行うモデル
param_grid : dict or list of dictionaries
パラメタ候補値を「パラメタ名, 候補値リスト」の辞書で与える
scoring : string, callable, list/tuple, dict or None, default: None
複数のメトリックを評価するには、文字例のリストか、の辞書で与える
n_jobs : int or None, optional (default=None)
同時実行数(-1にするとコア数で同時実行)
pre_dispatch : int, or string, optional
同時実行数にディスパッチされるジョブの数を設定する
iid : boolean, default=’warn’
Trueの場合、各テストセットのサンプル数で重み付けされた、折り畳み全体の平均スコアを返す
cv : int, cross-validation generator or an iterable, optional
Cross validationの分割数(デフォルト値は3)
refit : boolean, string, or callable, default=True
Trueだと最良だったパラメタを使い学習データ全体で再学習する
verbose : integer
ログ出力レベル(高ければ高いほど、長い出力)
error_score : ‘raise’ or numeric
エラーが発生した場合にスコアに割り当てる値。
return_train_score : boolean, default=False
Falseの場合は、トレーニングスコアを含まない
3)分析例
digitsのデータセットをGridSearchCVを使ってハイパーパラメータ最適化をします。
手書き数字(0~9)のデータセットdigitsをSVMで分類です。
SVMとはSupport Vector Machineの略で、学習データを用いて複数のクラスを分類する線を得て(学習モデル作成)、未知のデータ属する分類を推定する方法。
最適化時のモデルの評価関数にはf1を使用します。
ライブラリ
from sklearn import datasets from sklearn.model_selection import train_test_splitfrom sklearn.model_selection import GridSearchCVfrom sklearn.metrics import classification_reportfrom sklearn.svm import SVC import numpy as np import matplotlib.pyplot as plt
データセットのロード
0-9の数字の画像コードデータをロード
# sklernのライブラリからDigits dataset digits = datasets.load_digits() # X, y 作成 n_samples = len(digits.images) X = digits.images.reshape((n_samples, -1)) y = digits.target X, y
(array([[ 0., 0., 5., ..., 0., 0., 0.], [ 0., 0., 0., ..., 10., 0., 0.], [ 0., 0., 0., ..., 16., 9., 0.], ..., [ 0., 0., 1., ..., 6., 0., 0.], [ 0., 0., 2., ..., 12., 0., 0.], [ 0., 0., 10., ..., 12., 1., 0.]]), array([0, 1, 2, ..., 8, 9, 8]))
データセットの可視化
data_train = digits.images
label_train = digits.target
mean_images = np.zeros((10,8,8))
fig = plt.figure(figsize=(10,5))
for i in range(10):
mean_images[i] = data_train[label_train==i].mean(axis=0)
ax = fig.add_subplot(2, 5, i+1)
ax.axis('off')
ax.set_title('{0} (n={1})'.format(i, len(data_train[label_train==i])))
ax.imshow(mean_images[i],cmap=plt.cm.gray_r, interpolation='nearest')
plt.show()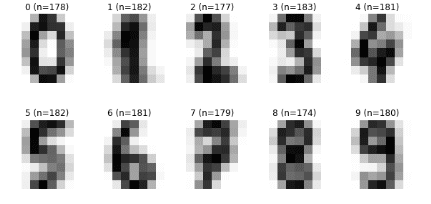
学習データとテストデータの割合
半分の学習データとテストデータに分けます。
X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.5, random_state=300)
ハイパーパラメータの調整
交差検定によってパラメータを設定します。
GridSearchCVで kernel、gamma、Cのパラメータを調整し、
最も評価のf1のモデルを探索します。
# 交差検定によってパラメータを設定
tuned_parameters = [{'kernel': ['rbf'],
'gamma': [1e-3, 1e-4],
'C': [1, 10, 100, 1000]},
{'kernel': ['linear'], 'C': [1, 10, 100, 1000]}]
scores = ['precision', 'recall']
for score in scores:
print("# ハイパーパラメータの調整: %s" % score)
print()
clf = GridSearchCV(SVC(), tuned_parameters, cv=5,
scoring='%s_macro' % score)
clf.fit(X_train, y_train)
print("最良のパラメータセット:")
print()
print(clf.best_params_)
print()
print("グリッドスコア: %s" % score)
print()
means = clf.cv_results_['mean_test_score']
stds = clf.cv_results_['std_test_score']
for mean, std, params in zip(means, stds, clf.cv_results_['params']):
print("%0.3f (+/-%0.03f) for %r"
% (mean, std * 2, params))
print()
print("詳細レポート:")
print()
print("学習データでモデルを作成")
print("テストデータの評価スコアを作成")
print()
y_true, y_pred = y_test, clf.predict(X_test)
print(classification_report(y_true, y_pred))
print()# ハイパーパラメータの調整: f1最良のパラメータセット:{'C': 1, 'gamma': 0.001, 'kernel': 'rbf'}グリッドスコア: f10.982 (+/-0.015) for {'C': 1, 'gamma': 0.001, 'kernel': 'rbf'}0.951 (+/-0.020) for {'C': 1, 'gamma': 0.0001, 'kernel': 'rbf'}0.982 (+/-0.015) for {'C': 10, 'gamma': 0.001, 'kernel': 'rbf'}0.976 (+/-0.021) for {'C': 10, 'gamma': 0.0001, 'kernel': 'rbf'}0.982 (+/-0.015) for {'C': 100, 'gamma': 0.001, 'kernel': 'rbf'}0.980 (+/-0.017) for {'C': 100, 'gamma': 0.0001, 'kernel': 'rbf'}0.982 (+/-0.015) for {'C': 1000, 'gamma': 0.001, 'kernel': 'rbf'}0.980 (+/-0.017) for {'C': 1000, 'gamma': 0.0001, 'kernel': 'rbf'}0.975 (+/-0.026) for {'C': 1, 'kernel': 'linear'}0.975 (+/-0.026) for {'C': 10, 'kernel': 'linear'}0.975 (+/-0.026) for {'C': 100, 'kernel': 'linear'}0.975 (+/-0.026) for {'C': 1000, 'kernel': 'linear'}詳細レポート:学習データでモデルを作成テストデータの評価スコアを作成precision recall f1-score support0 1.00 0.98 0.99 1331 0.96 1.00 0.98 1312 1.00 0.99 1.00 1253 0.99 0.91 0.95 1324 0.98 0.99 0.99 1215 0.98 0.97 0.97 1276 0.99 0.99 0.99 1257 0.98 0.99 0.98 1278 0.90 0.95 0.92 1159 0.98 0.98 0.98 122micro avg 0.98 0.98 0.98 1258macro avg 0.98 0.98 0.98 1258weighted avg 0.98 0.98 0.98 1258結果
最も良い評価のf1のハイパーパラメータは C = 10, gamma = 0.001, kernel = rbfです。
{‘C’: 10, ‘gamma’: 0.001, ‘kernel’: ‘rbf’}
f1-score:1.00
詳細:
sklearn.model_selection.GridSearchCV