
目次
1. 半教師あり学習の概要
1.1 半教師あり学習とは
1.2 ラベル拡散法 (label spreading)
2. 実験
2.1 環境準備
2.2 データ準備
2.3 ラベル拡散法モデル学習
2.4 分類モデル学習
2.5 まとめ
1. 半教師あり学習の概要
1.1 半教師あり学習とは
半教師あり学習(Semi-Supervised Learning)とは教師あり学習と教師なし学習を組み合わせて学習する方法です。教師あり学習はラベル付きデータでモデルを作成します。例えば、ネゴの画像と犬の画像の分類問題です。教師なし学習はラベルなしデータでモデルを作成します。例えば、複数画像の特徴から、クラスターを作成します。
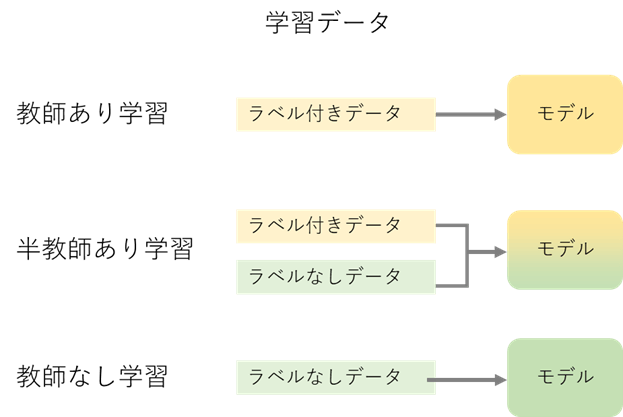
1.2 ラベル拡散法 (label spreading)
正確なモデルを予測するための十分なラベル付きデータがなく、より多くのデータを取得するための能力またはリソースがない場合は、半教師あり手法を使用してトレーニングデータの規模を大きくすることができます。半教師あり学習アルゴリズムを使用してデータにラベルを付け、新しくラベルが付けられたデータセットでモデルを再トレーニングします。
scikit-learnにはラベル拡散法 (label spreading) が実装されており,あるデータのラベルを予測する事によってラベルのないデータにコピーする (伝播させる) ことで,少量のラベル付きデータからモデルを学習します。
| sklearn.semi_supervised.LabelSpreading(kernel=’rbf’, *, gamma=20, n_neighbors=7, alpha=0.2, max_iter=30, tol=0.001, n_jobs=None) |
2. 実験
データセット:iris (アヤメの種類と特徴量に関する分類データセット)
モデル:ラベル拡散法 (label spreading) ⇒ランダムフォレスト
モデル評価;Accuracy
2.1 環境準備
ライブラリのインポート
| import numpy as np import pandas as pd
#SK-Learn Libraries from sklearn.model_selection import train_test_split from sklearn.semi_supervised import LabelSpreading from sklearn import datasets from sklearn.metrics import accuracy_score from sklearn.ensemble import RandomForestClassifier |
2.2 データ準備
Sklearnからirisのデータセットをロードします。
| #Load Data iris = datasets.load_iris() |
データ確認
| print(“Total Records: “, len(iris.data)) iris |
Total Records: 150
{‘DESCR’: ‘.. _iris_dataset:\n\nIris plants dataset\
…
‘data’: array([[5.1, 3.5, 1.4, 0.2],
[4.9, 3. , 1.4, 0.2],
…
[5.9, 3. , 5.1, 1.8]]),
‘feature_names’: [‘sepal length (cm)’,
‘sepal width (cm)’,
‘petal length (cm)’,
‘petal width (cm)’],
‘filename’: ‘/usr/local/lib/python3.7/dist-packages/sklearn/datasets/data/iris.csv’,
‘target’: array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2]),
‘target_names’: array([‘setosa’, ‘versicolor’, ‘virginica’], dtype='<U10′)}
半分のデータセットはラベルなしに加工します。
| # 乱数作成 rng = np.random.RandomState(111)
#ラベルを付けないサンプルの数を定義する random_unlabeled_points = rng.rand(len(iris.target)) <= 0.5
#ラベルなしに設定する Unlabeled = np.copy(iris.target) Unlabeled[random_unlabeled_points] = -1
|
ラベルなしの確認
| Unlabeled |
array([ 0, -1, -1, 0, -1, -1, -1, -1, -1, -1, 0, -1, -1, 0, 0, -1, -1,
-1, -1, 0, 0, 0, 0, 0, 0, 0, -1, -1, -1, -1, 0, 0, 0, -1,
0, -1, 0, -1, -1, 0, -1, -1, -1, 0, 0, 0, -1, 0, 0, 0, -1,
1, -1, -1, -1, -1, -1, -1, -1, -1, 1, -1, -1, -1, 1, -1, 1, 1,
-1, 1, -1, 1, -1, 1, -1, 1, 1, -1, 1, -1, -1, -1, -1, -1, -1,
-1, 1, 1, -1, 1, 1, -1, -1, 1, 1, -1, 1, 1, -1, 1, -1, -1,
-1, 2, 2, 2, -1, 2, -1, 2, 2, -1, 2, 2, -1, 2, 2, 2, -1,
-1, 2, -1, 2, -1, 2, -1, -1, -1, -1, -1, -1, 2, -1, 2, -1, 2,
2, 2, 2, -1, 2, -1, -1, -1, -1, -1, 2, -1, 2, -1])
2.3 ラベル拡散法モデル学習
ラベル拡散法 (label spreading)を学習します。
| # ラベル拡散法 label_prop_model = LabelSpreading()
# ラベル拡散法を学習する label_prop_model.fit(iris.data, Unlabeled)
#ラベルのなしを予測する pred_lb = label_prop_model.predict(iris.data)
#Accuracy print(“Accuracy of Label Spreading: “,'{:.2%}’.format(label_prop_model.score(iris.data,pred_lb))) |
Accuracy of Label Spreading: 100.00%
2.4 分類モデル学習
ランダムフォレスト分類モデルを学習します。
| X = iris.data y = pred_lb
# データセットの分割[train = 90%, test = 10%] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.1, random_state=0)
# モデルの定義 model = RandomForestClassifier(verbose = 0, max_depth=2, random_state=0)
# モデル学習 model.fit(X_train,y_train)
# 推論 rf_pred = model.predict(X_test)
# Accuracy acc = accuracy_score(y_test, rf_pred) print(“Random Forest Model Accuracy (after Label Spreading): “,'{:.2%}’.format(acc)) |
Random Forest Model Accuracy (after Label Spreading): 93.33%
2.5 まとめ
半教師あり学習は教師あり学習と教師なし学習を組み合わせて学習する方法です。今回はirisの加工したデータ(ラベル無しを作成)でラベル拡散法 (label spreading)を用いました。そして、できたラベルデータでランダムフォレスト分類モデルを学習しました。少量のラベル付きデータからモデルをラベル拡散によって使えるデータが増えました。

担当者:KW
バンコクのタイ出身 データサイエンティスト
製造、マーケティング、財務、AI研究などの様々な業界にPSI生産管理、在庫予測・最適化分析、顧客ロイヤルティ分析、センチメント分析、SaaS、PaaS、IaaS、AI at the Edge の環境構築などのスペシャリスト