
前回の記事はランダムフォレスト(Random Forest)について解説しました。今回はランダムフォレストに似ているExtraTreesについて解説します。
関連記事: 決定木分析、ランダムフォレスト、Xgboost、CatBoost、LightGBM
目次:
1. エクストラツリー ExtraTreesとは
2. エクストラツリー ExtraTreesの特徴
3. SklearnのExtraTreesのパラメーター
4. 実験・コード
__4.1 データ読み込み
__4.2 決定木、ランダムフォレスト、ExtraTrees
__4.3 モデル評価
1. エクストラツリー ExtraTreesとは
ExtraTrees とは Extremely Randomized Treesの略称です。ExtraTreesClassifierは、基本的に決定木に基づくアンサンブル学習方法です。RandomForestのようなExtraTreesClassifierは、特定の決定とデータのサブセットをランダム化して、データからの過剰学習をランダムフォレストよりも少なくすることを想定されています。
論文はこれになります。
Extremely randomized trees
Pierre Geurts · Damien Ernst · Louis Wehenkel
https://link.springer.com/content/pdf/10.1007/s10994-006-6226-1.pdf
2. エクストラツリー ExtraTreesの特徴
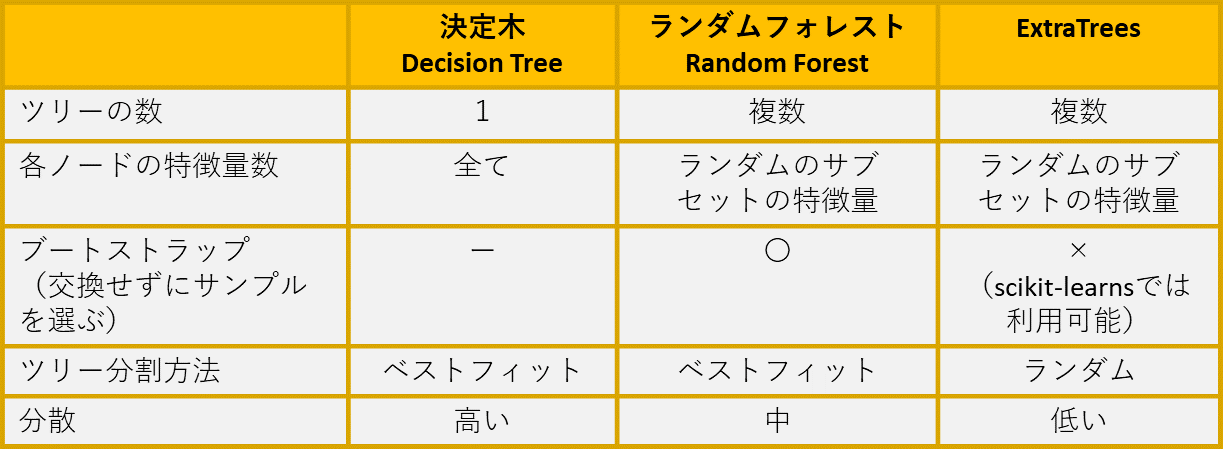
決定木とランダムフォレストとExtraTreesを比較します。
決定木
通常、単一の決定木はめ、学習元のデータに対してオーバーフィッテングになりやすいです。通常、ランダムフォレストのほうが精度高い事が多いです。
ランダムフォレスト
ランダムフォレストモデルは、複数ツリー(n_estimators)を作成し、過学習を減らす事が出来ます。
Extra Trees
Extra Treesはランダムフォレストに似ています。複数のツリーを構築する所は、一緒ですが、木のノード(葉)を分割する所の特徴量(ジニ係数、エントロピー)のどちらかをランダムに選びます。
3. SklearnのExtraTreesのパラメーター
class sklearn.ensemble.ExtraTreesClassifier(n_estimators=100, criterion=’gini’, max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=’auto’, max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, bootstrap=False, oob_score=False, n_jobs=None, random_state=None, verbose=0, warm_start=False, class_weight=None, ccp_alpha=0.0, max_samples=None)
n_estimator:フォレスト内のツリーの数(10~100)「int」
criterion:サポートされる基準は、Gini不純物の「gini」および情報ゲインの「entropy」です。
max_depth:ツリーの最大の深さ「int」
min_samples_split:内部ノードを分割するために必要なサンプルの最小数「int」
min_samples_leaf:リーフノードにあるために必要なサンプルの最小数「int」
min_weight_fraction_leaf:リーフノードに存在する必要がある(すべての入力サンプルの)重みの合計の最小重み付き割合 「int」
max_features:最適な分割をする特徴量数「int」「float」「auto」「sqrt」「log2」
max_leaf_nodes:リーフノードの最大値 「int」
min_impurity_decrease:この分割がこの値以上の不純物の減少を引き起こす場合、ノードは分割されます。
min_impurity_split:木の成長の早期停止のしきい値
oob_score:一般化の精度を推定するためにアウトオブバッグサンプル
n_jobs:並行して実行するジョブの数
random_state:乱数を制御するパラメータ
bootstrapping:ツリーの構築時に使用されるサンプルのブートストラップの設定
4. 実験・コード
データセット:scikit-learnで提供されている癌の判定を行うデータ
モデル:決定木、ランダムフォレスト、ExtraTrees、ExtraTrees (bootstrap)
モデル評価: 学習データの5分割交差検証、テストの精度 (Accuracy)
# ライブラリのインポート
import pandas as pd
import numpy as np
from datetime import datetime
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn import model_selection
from sklearn.ensemble import ExtraTreesClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
seed = 0
# サンプルデータロード
loaded_data = load_breast_cancer()
X_train, X_test, y_train, y_test = train_test_split(loaded_data.data, loaded_data.target, random_state=seed)
kfold = model_selection.KFold(n_splits = 5)
scores = {}
# 決定木
start_time = datetime.now()
dtc_clf = DecisionTreeClassifier(random_state=seed)
dtc_clf.fit(X_train, y_train)
results = model_selection.cross_val_score(dtc_clf, X_test, y_test, cv = kfold)
end_time = datetime.now()
scores[('1.decision_tree', 'duration')] = end_time - start_time
scores[('1.decision_tree', 'train_score')] = results.mean()
scores[('1.decision_tree', 'test_score')] = dtc_clf.score(X_test, y_test)
# ランダムフォレスト
start_time = datetime.now()
rfc_clf = RandomForestClassifier(random_state=seed)
rfc_clf.fit(X_train, y_train)
results = model_selection.cross_val_score(rfc_clf, X_test, y_test, cv = kfold)
end_time = datetime.now()
scores[('2.Random Forest', 'duration')] = end_time - start_time
scores[('2.Random Forest', 'train_score')] = results.mean()
scores[('2.Random Forest', 'test_score')] = rfc_clf.score(X_test, y_test)
# Extra Tree
start_time = datetime.now()
ext_clf = ExtraTreesClassifier(random_state=seed)
ext_clf.fit(X_train, y_train)
results = model_selection.cross_val_score(ext_clf, X_test, y_test, cv = kfold)
end_time = datetime.now()
scores[('3.extra_tree', 'duration')] = end_time - start_time
scores[('3.extra_tree', 'train_score')] = results.mean()
scores[('3.extra_tree', 'test_score')] = ext_clf.score(X_test, y_test)
# Extra Tree + bootstrap
start_time = datetime.now()
extb_clf = ExtraTreesClassifier(bootstrap=True, random_state=seed)
extb_clf.fit(X_train, y_train)
results = model_selection.cross_val_score(extb_clf, X_test, y_test, cv = kfold)
end_time = datetime.now()
scores[('4.extra_tree (bootstrap)', 'duration')] = end_time - start_time
scores[('4.extra_tree (bootstrap)', 'train_score')] = results.mean()
scores[('4.extra_tree (bootstrap)', 'test_score')] = ext_clf.score(X_test, y_test)
# モデル評価
pd.Series(scores).unstack()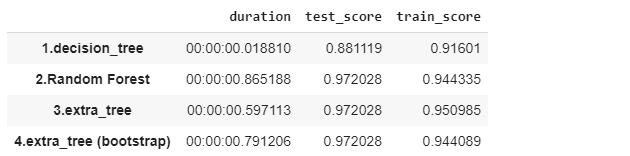
まとめ
今回は決定機、ランダムフォレスト、ExtraTreesのモデルを解説と実験しました。実験はbreast_cancerのデータセットとデフォルトのパラメータにして、決定木、ランダムフォレスト、ExtraTrees、ExtraTrees (Boosting)を実行しました。ExtraTreesはテストと学習のスコアの精度が一番高いです。ExtraTreeの学習期間は決定機より遅いですが、ランダムフォレストより速いです。また、extra_tree (Boosting)は実行時間が増やしますが、制度がない結果になります。