前回はアンサンブル学習のアルゴリズムを開設しました。アンサンブル学習のアルゴリズムは、同じ学習アルゴリズムの多数のEstimatorからの予測結果を組み合わせた技術である。今回は様々なアンサンブル学習手法を解説と実験したいと思います。
目次
1. アンサンブル学習の概要
___1.1 アンサンブル学習(Ensemble learning)とは
___1.2 バイアス(Bias)とバリアンス(Variance)
2. 基本的なアンサンブル学習
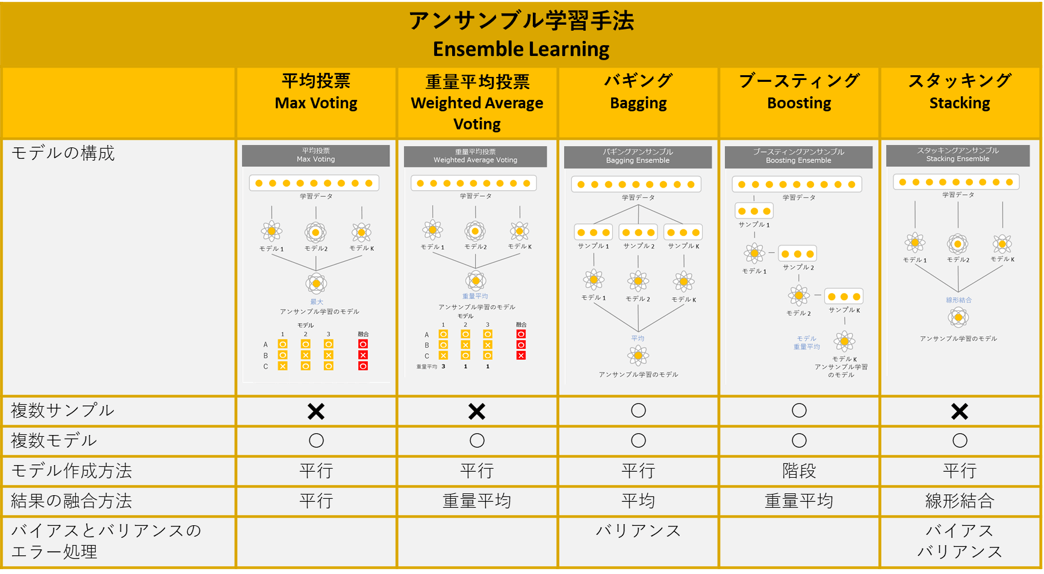
___2.1 Max Voting
___2.2 Weighted Average Voting
3. 高度なアンサンブル学習
___3.1 Bagging
___3.2 Boosting
___3.3 Stacking
4. まとめ
1. アンサンブル学習の概要
1.1 アンサンブル学習(Ensemble learning)とは
アンサンブル学習とは、(英:ensemble learning)とは日本語で合奏を意味します。その名の通り、簡単に言えば多数決をとる方法です。個々に別々の学習器として学習させたものを、融合させる事によって、未学習のデータに対しての予測能力を向上させるための学習です。
ビジネス判断に考えると、アンサンブル学習は1人で問題を解くより、複数人で意見を出し合って知識を補い合いながら解く方が、正答率上がるということになっています。
Kaggleなどのデータ解析競技には、頻繁にこの「アンサンブル学習」の話題が上がります。事実、多くのコンペティションの上位にランクインする方々はアンサンブル学習を活用しています。
1.2 バイアス(Bias)とバリアンス(Variance)
アンサンブル学習を理解する上で前提となる知識、「バイアス(Bias)」「バリアンス(Variance)」の2つを説明します。機械学習の精度を向上するということは「予測値」と「実際値」の誤差を最小化することですが、その誤差をより的確に理解するために「バイアス」「バリアンス」が用いられます。
下の図は青い点が機械学習モデルの予測した値、赤い点がデータの実際の値を図式化したものです。
バイアス(Bias)は、推定値と実際値の平均的な違い。高いバイアス エラーは、性能が悪いモデルで、データ中の重要なトレンドを見逃します。
バリアンス(Variance)同じ観測で推定値の異なり具合。バリアンスが高いモデルは訓練データに当てはまりすぎて、訓練外では性能が悪いです。
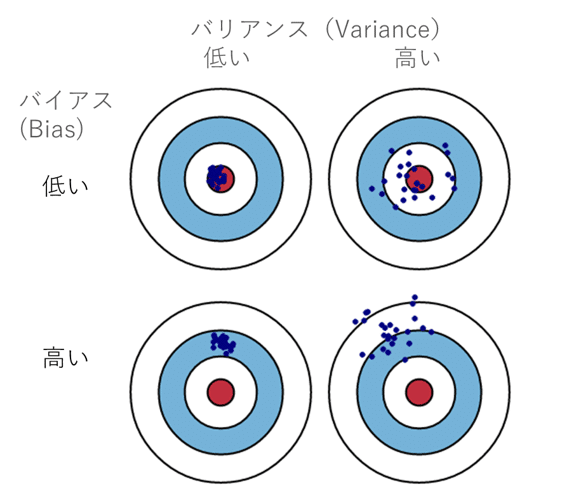
低バイアスの状態(予測値と実際値の誤差が少ない)になりますが、その一方でバリアンスは高まり過学習に陥るケースがあります。良いモデルはバイアスとバリアンスの最も適切なバランスを調整してモデルの精度を向上させていきます。
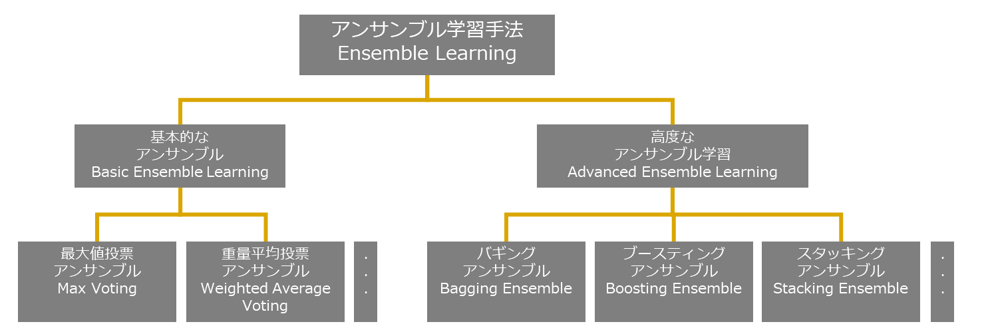
アンサンブル学習の種類
アンサンブル学習の大まかな分類は以下になります。基本的なアンサンブルと高度なアンサンブル学習手法の大分類があります。(以下図の以外の方法もあります)
2. 基本的なアンサンブル学習手法
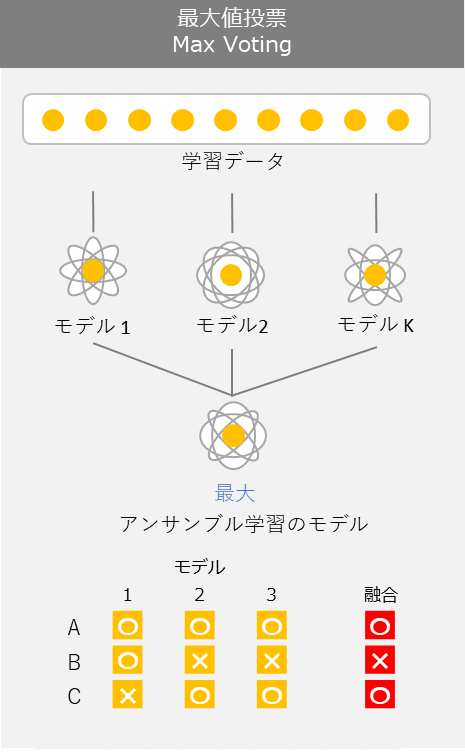
2.1 Max Voting
Max Votingは異なる機械学習分類器を組み合わせ、多数決や予測の平均投票を使用し、クラスラベルを予測することです。そのような分類器は個々の弱点を相殺するため、モデルの生成に有効である場合もあります。
複数のモデルを訓練して各モデルの予測を最終的に多数決して決めます。
実験・コード
データセット:scikit-learnで提供されている癌の判定を行うデータ
モデル:ロジスティック回帰、決定木、サポートベクターマシン、Max Votingアンサンブル
モデル評価: 学習データの5分割交差検証、テストの精度 (Accuracy)
# Max Voting
# ライブラリのインポート
import pandas as pd
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn import model_selection
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.svm import SVC
from sklearn.ensemble import VotingClassifier
seed = 0
# サンプルデータロード
loaded_data = load_breast_cancer()
X_train, X_test, y_train, y_test = train_test_split(loaded_data.data, loaded_data.target, random_state=seed)
kfold = model_selection.KFold(n_splits = 5)
scores = {}
# ロジスティック回帰
lr_clf = LogisticRegression(solver='lbfgs', max_iter=10000)
lr_clf.fit(X_train, y_train)
results = model_selection.cross_val_score(lr_clf, X_test, y_test, cv = kfold)
scores[('1.Logistic_regression', 'train_score')] = results.mean()
scores[('1.Logistic_regression', 'test_score')] = lr_clf.score(X_test, y_test)
# 決定木
dtc_clf = DecisionTreeClassifier(random_state=seed)
dtc_clf.fit(X_train, y_train)
results = model_selection.cross_val_score(dtc_clf, X_test, y_test, cv = kfold)
scores[('2.decision_tree', 'train_score')] = results.mean()
scores[('2.decision_tree', 'test_score')] = dtc_clf.score(X_test, y_test)
# サポートベクターマシン(SVM)
svm_clf = SVC(probability=True, random_state=seed)
svm_clf.fit(X_train, y_train)
results = model_selection.cross_val_score(svm_clf, X_test, y_test, cv = kfold)
scores[('3.SVM', 'train_score')] = results.mean()
scores[('3.SVM', 'test_score')] = svm_clf.score(X_test, y_test)
# バギングアンサンブル
estimators=[('lr', lr_clf), ('dtc', dtc_clf), ('svc', svm_clf)]
vote_clf=VotingClassifier(estimators=estimators, voting='hard')
vote_clf.fit(X_train, y_train)
results = model_selection.cross_val_score(vote_clf, X_test, y_test, cv = kfold)
scores[('4.Max_voting', 'train_score')] = results.mean()
scores[('4.Max_voting', 'test_score')] = vote_clf.score(X_test, y_test)
# モデル評価
pd.Series(scores).unstack()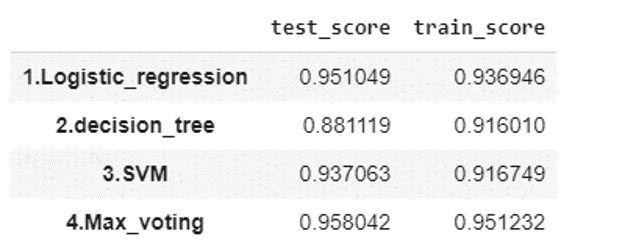
それぞれのモデルごとに計測した性能が出力されます。単体のモデルの中、ロジスティック回帰は一番良い精度になっています。また、三つのモデルの平均結果アンサンブルはより良い精度ができました。学習とテストの結果が上がっています。
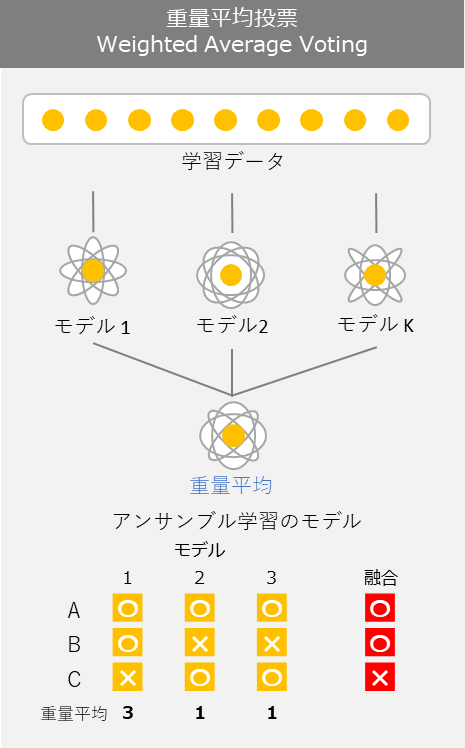
2.2 Weighted Average Voting 重量平均投票
重量平均は Max Votingと同様に異なる機械学習分類器を組み合わせが、多数決や予測の重量平均投票を使用します。重量平均は特定に設定することができます。
実験・コード
データセット:scikit-learnで提供されている癌の判定を行うデータ
モデル:ロジスティック回帰、決定木、サポートベクターマシン、Weighted Average Votingアンサンブル
モデル評価: 学習データの5分割交差検証、テストの精度 (Accuracy)
# Weight Average Voting
# ライブラリのインポート
import pandas as pd
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn import model_selection
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.svm import SVC
from sklearn.ensemble import VotingClassifier
seed = 0
# サンプルデータロード
loaded_data = load_breast_cancer()
X_train, X_test, y_train, y_test = train_test_split(loaded_data.data, loaded_data.target, random_state=seed)
kfold = model_selection.KFold(n_splits = 5)
scores = {}
# ロジスティック回帰
lr_clf = LogisticRegression(solver='lbfgs', max_iter=10000)
lr_clf.fit(X_train, y_train)
results = model_selection.cross_val_score(lr_clf, X_test, y_test, cv = kfold)
scores[('1.Logistic_regression', 'train_score')] = results.mean()
scores[('1.Logistic_regression', 'test_score')] = lr_clf.score(X_test, y_test)
# 決定木
dtc_clf = DecisionTreeClassifier(random_state=seed)
dtc_clf.fit(X_train, y_train)
results = model_selection.cross_val_score(dtc_clf, X_test, y_test, cv = kfold)
scores[('2.decision_tree', 'train_score')] = results.mean()
scores[('2.decision_tree', 'test_score')] = dtc_clf.score(X_test, y_test)
# サポートベクターマシン(SVM)
svm_clf = SVC(probability=True, random_state=seed)
svm_clf.fit(X_train, y_train)
results = model_selection.cross_val_score(svm_clf, X_test, y_test, cv = kfold)
scores[('3.SVM', 'train_score')] = results.mean()
scores[('3.SVM', 'test_score')] = svm_clf.score(X_test, y_test)
# バギングアンサンブル Max Voting
estimators=[('lr', lr_clf), ('dtc', dtc_clf), ('svc', svm_clf)]
vote_clf=VotingClassifier(estimators=estimators, voting='hard')
vote_clf.fit(X_train, y_train)
results = model_selection.cross_val_score(vote_clf, X_test, y_test, cv = kfold)
scores[('4.Max_voting', 'train_score')] = results.mean()
scores[('4.Max_voting', 'test_score')] = vote_clf.score(X_test, y_test)
# バギングアンサンブル Weighted Average Voting
dtc = DecisionTreeClassifier(random_state=seed)
estimators=[('lr', lr_clf), ('dtc', dtc_clf), ('svc', svm_clf)]
vote_clf=VotingClassifier(estimators=estimators, voting='soft', weights=[3, 1, 1])
vote_clf.fit(X_train, y_train)
results = model_selection.cross_val_score(vote_clf, X_test, y_test, cv = kfold)
scores[('5.Weight_Average_voting', 'train_score')] = results.mean()
scores[('5.Weight_Average_voting', 'test_score')] = vote_clf.score(X_test, y_test)
# モデル評価
pd.Series(scores).unstack()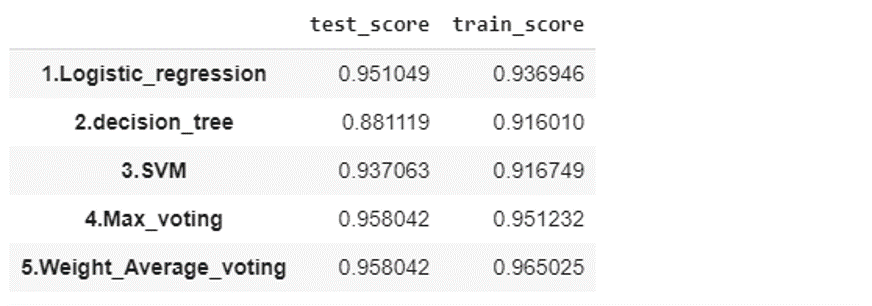
ロジスティック回=3、決定木=1、サポートベクターマシン=1の重量を追加して、より良いモデルができました。重量平均のアンサンブル学習は学習データの精度は96%に上がっています。
3. 高度なアンサンブル学習手法
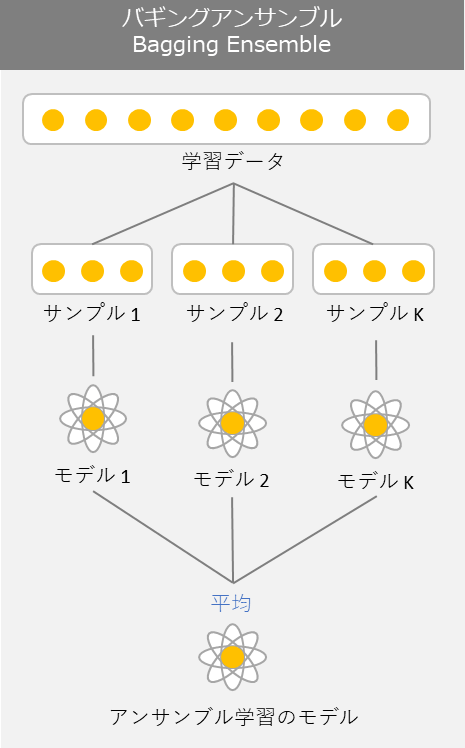
3.3 Bagging (バギング)
バギングではブートストラップ手法を用いて学習データを復元抽出することによってデータセットに多様性を持たせています。復元抽出とは、一度抽出したサンプルが再び抽出の対象になるような抽出方法です。バギングとは一般的にモデルの予測結果のバリアンスを低くする特徴があります。つまり少し大雑把に言えば、予測値と実際値の誤差が大きい場合の改善方法です。例えば 下記のようにバギングの手法を使って3つのモデルを組み合わせて予測精度の改善を行うとしましょう。
実験・コード
データセット:scikit-learnで提供されている癌の判定を行うデータ
モデル:決定木とバギングアンサンブルの決定木
モデル評価: 学習データの5分割交差検証、テストの精度 (Accuracy)
# ライブラリのインポート
import pandas as pd
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn import model_selection
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import BaggingClassifier
seed = 0
# サンプルデータロード
loaded_data = load_breast_cancer()
X_train, X_test, y_train, y_test = train_test_split(loaded_data.data, loaded_data.target, random_state=seed)
kfold = model_selection.KFold(n_splits = 5)
scores = {}
# 決定木
dtc_clf = DecisionTreeClassifier(random_state=seed)
dtc_clf.fit(X_train, y_train)
results = model_selection.cross_val_score(dtc_clf, X_test, y_test, cv = kfold)
scores[('1.decision_tree', 'train_score')] = results.mean()
scores[('1.decision_tree', 'test_score')] = dtc_clf.score(X_test, y_test)
# バギングアンサンブルの決定木
bag_model=BaggingClassifier(base_estimator=dtc_clf, n_estimators=100, random_state=seed)
bag_model.fit(X_train, y_train)
results = model_selection.cross_val_score(bag_model, X_test, y_test, cv = kfold)
scores[('2.decision_tree_bagging', 'train_score')] = results.mean()
scores[('2.decision_tree_bagging', 'test_score')] = bag_model.score(X_test, y_test)
# モデル評価
pd.Series(scores).unstack()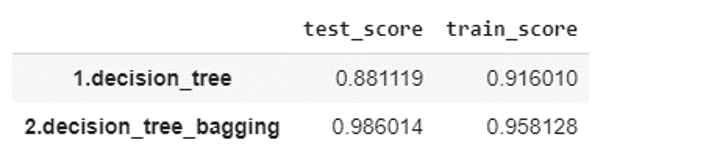
基本の決定木よりバギングアンサンブルの決定木の方が性能良いという結果になっています。
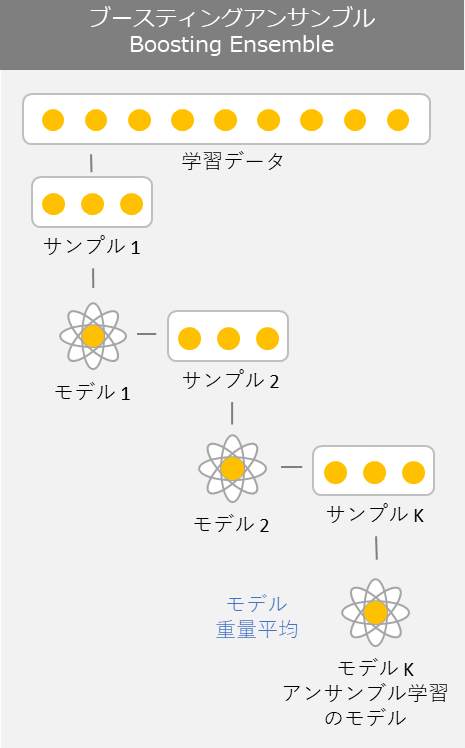
3.4 Boosting (ブースティング)
ブースティングはバギングと同様に複数のモデルを利用するわけですが、バギングとは利用の仕方が異なります。ブースティングは基本となるモデルを最初に訓練してベースラインを設けます。このベースラインとした基本モデルに対して何度も反復処理を行い改善行なっていきます。ブースティングは、一般的にモデルの予測精度に対してバイアスを下げる特徴があります。
実験・コード
データセット:scikit-learnで提供されている癌の判定を行うデータ
モデル:ロジスティック回帰、決定木
アンサンブル学習のアルゴリズム:
-ランダムフォレスト
– AdaBoost
– GradientBoosting
– Xgboost
– lightGBM
– CatBoost
モデル評価: 学習データの5分割交差検証、テストの精度 (Accuracy)
# Boosting
# ライブラリのインポート
import pandas as pd
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn import model_selection
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import AdaBoostClassifier
from sklearn.ensemble import GradientBoostingClassifier
from xgboost import XGBClassifier
from lightgbm import LGBMClassifier
from catboost import CatBoostClassifier
seed = 0
# サンプルデータロード
loaded_data = load_breast_cancer()
X_train, X_test, y_train, y_test = train_test_split(loaded_data.data, loaded_data.target, random_state=seed)
kfold = model_selection.KFold(n_splits = 5)
scores = {}
# ロジスティック回帰
lr_clf = LogisticRegression(solver='lbfgs', max_iter=10000)
lr_clf.fit(X_train, y_train)
results = model_selection.cross_val_score(lr_clf, X_test, y_test, cv = kfold)
scores[('1.Logistic_regression', 'train_score')] = results.mean()
scores[('1.Logistic_regression', 'test_score')] = lr_clf.score(X_test, y_test)
# 決定木
dtc_clf = DecisionTreeClassifier(random_state=seed)
dtc_clf.fit(X_train, y_train)
results = model_selection.cross_val_score(dtc_clf, X_test, y_test, cv = kfold)
scores[('2.decision_tree', 'train_score')] = results.mean()
scores[('2.decision_tree', 'test_score')] = dtc_clf.score(X_test, y_test)
# ランダムフォレスト
rfc_clf = RandomForestClassifier(max_depth=5, random_state=seed)
rfc_clf.fit(X_train, y_train)
results = model_selection.cross_val_score(rfc_clf, X_test, y_test, cv = kfold)
scores[('3.Random Forest', 'train_score')] = results.mean()
scores[('3.Random Forest', 'test_score')] = rfc_clf.score(X_test, y_test)
# AdaBoost
adb_clf = AdaBoostClassifier(n_estimators=100, random_state=seed)
adb_clf.fit(X_train, y_train)
results = model_selection.cross_val_score(adb_clf, X_test, y_test, cv = kfold)
scores[('4.AdaBoost', 'train_score')] = results.mean()
scores[('4.AdaBoost', 'test_score')] = adb_clf.score(X_test, y_test)
# GradientBoosting (GBM)
gbm_clf = GradientBoostingClassifier(random_state=seed)
gbm_clf.fit(X_train, y_train)
results = model_selection.cross_val_score(gbm_clf, X_test, y_test, cv = kfold)
scores[('5.GBM', 'train_score')] = results.mean()
scores[('5.GBM', 'test_score')] = gbm_clf.score(X_test, y_test)
# xgboost
xgb_clf = XGBClassifier()
xgb_clf.fit(X_train, y_train)
results = model_selection.cross_val_score(xgb_clf, X_test, y_test, cv = kfold)
scores[('6.xgboost', 'train_score')] = results.mean()
scores[('6.xgboost', 'test_score')] = xgb_clf.score(X_test, y_test)
# lightGBM
lgbm_clf = LGBMClassifier(eval_metric='accuracy')
lgbm_clf.fit(X_train, y_train)
results = model_selection.cross_val_score(lgbm_clf, X_test, y_test, cv = kfold)
scores[('7.lightGBM', 'train_score')] = results.mean()
scores[('7.lightGBM', 'test_score')] = lgbm_clf.score(X_test, y_test)
# CatBoost
ctb_clf = CatBoostClassifier(eval_metric="Accuracy", logging_level='Silent')
ctb_clf.fit(X_train, y_train)
results = model_selection.cross_val_score(ctb_clf, X_test, y_test, cv = kfold)
scores[('8.CatBoost', 'train_score')] = results.mean()
scores[('8.CatBoost', 'test_score')] = ctb_clf.score(X_test, y_test)
# モデル評価
pd.Series(scores).unstack()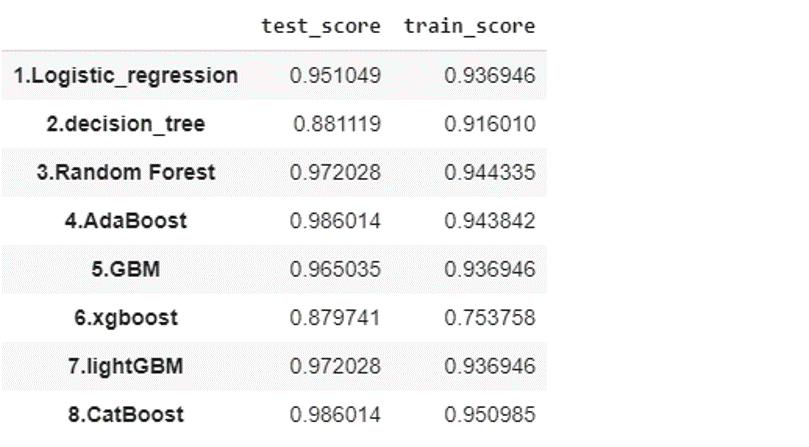
各アンサンブル学習のアルゴリズム(ロジスティクスと決定木の以外)を実行しました。デフォルトの設定にしても、アンサンブル学習のアルゴリズムの精度が高いになっています。
各アンサンブル学習のアルゴリズムの詳細説明は下記になります。
・GBM
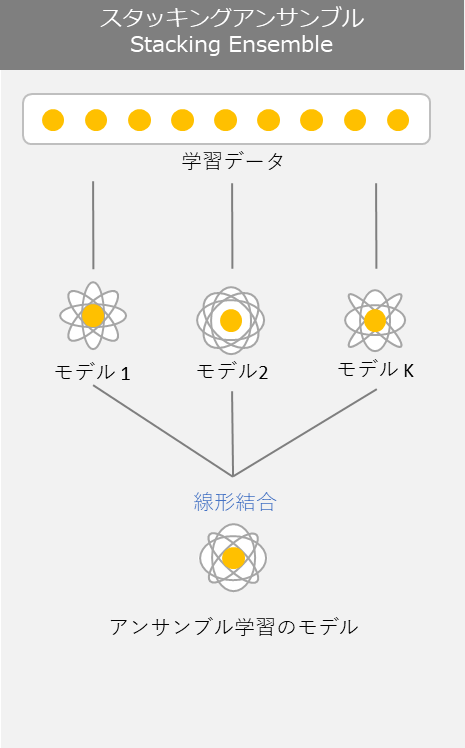
3.1 Stacking (スタッキング)
スタッキングアンサンブルとは言葉の通りモデルを積み上げていく方法です。スタッキングの主な仕組みとしては、二段階に積み上げるとします。まず、第一段階で様々な学習器です。 学習器によって正解率が高いものと低いものがあるので、より正解率の高い学習器のみを組み合わせることによって、ランダムで組み合わせるよりも精度が高くなります。上手く利用することによりバイアスとバリアンスをバランスよく調整する事が可能です。
Kaggleなどの機械学習コンペで上位に入ってくるアルゴリズムの多くに、このスタッキングという手法が取り入れられています。
実験・コード
データセット:scikit-learnで提供されている癌の判定を行うデータ
モデル:ロジスティック回帰、決定木、サポートベクターマシン、スタッキングアンサンブル
モデル評価: 学習データの5分割交差検証、テストの精度 (Accuracy)
# Stacking
# ライブラリのインポート
import pandas as pd
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn import model_selection
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.svm import SVC
from sklearn.ensemble import StackingClassifier
seed = 0
# サンプルデータロード
loaded_data = load_breast_cancer()
X_train, X_test, y_train, y_test = train_test_split(loaded_data.data, loaded_data.target, random_state=seed)
kfold = model_selection.KFold(n_splits = 5)
scores = {}
# ロジスティック回帰
lr_clf = LogisticRegression(solver='lbfgs', max_iter=10000)
lr_clf.fit(X_train, y_train)
results = model_selection.cross_val_score(lr_clf, X_test, y_test, cv = kfold)
scores[('1.Logistic_regression', 'train_score')] = results.mean()
scores[('1.Logistic_regression', 'test_score')] = lr_clf.score(X_test, y_test)
# 決定木
dtc_clf = DecisionTreeClassifier(random_state=seed)
dtc_clf.fit(X_train, y_train)
results = model_selection.cross_val_score(dtc_clf, X_test, y_test, cv = kfold)
scores[('2.decision_tree', 'train_score')] = results.mean()
scores[('2.decision_tree', 'test_score')] = dtc_clf.score(X_test, y_test)
# サポートベクターマシン(SVM)
svm_clf = SVC(probability=True, random_state=seed)
svm_clf.fit(X_train, y_train)
results = model_selection.cross_val_score(svm_clf, X_test, y_test, cv = kfold)
scores[('3.SVM', 'train_score')] = results.mean()
scores[('3.SVM', 'test_score')] = svm_clf.score(X_test, y_test)
# バギングアンサンブル
estimators=[('lr', lr_clf), ('dtc', dtc_clf), ('svc', svm_clf)]
stk_clf=StackingClassifier(estimators=estimators, final_estimator=LogisticRegression())
stk_clf.fit(X_train, y_train)
results = model_selection.cross_val_score(stk_clf, X_test, y_test, cv = kfold)
scores[('4.Stacking', 'train_score')] = results.mean()
scores[('4.Stacking', 'test_score')] = stk_clf.score(X_test, y_test)
# モデル評価
pd.Series(scores).unstack()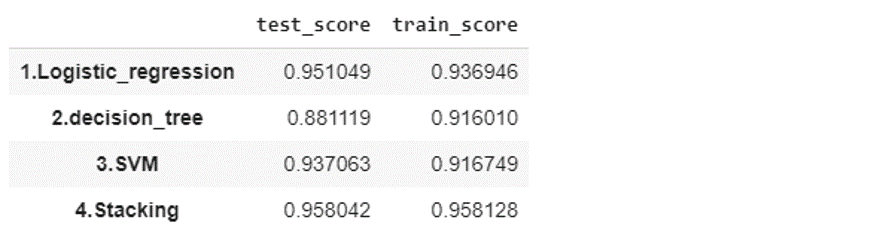
それぞれのモデルごとに計測した性能が出力されます。単体のモデルの中よりスタッキングアンサンブルの方が良い精度になっています。学習とテストの結果が上がっていました。
まとめ
今回の記事は様々なアンサンブル学習を解説と実験しました。アンサンブルは各モデルの強みを合わせてより良い予測モデルができました。あるアンサンブル学習手法に対してどちらの手法が最良かは解析目的の問題で、置かれた状況の詳細によります。