
目次
1. 欠損値とは
2. MCARとは
3. MARとは
4. MNARとは
5. 欠損値の削除
5.1リストワイズ除去法 (listwise deletion)
5.2 ペアワイズ除去法 (pairwise deletion)
6. 代入法(imputation)
_6.1 一変量代入法(Univariate feature Imputation)
_6.2 多変量代入法(Multivariate feature imputation)
1. 欠損値とは
場合によっては全てのデータが得られていない場合があります。実際の集計には使われないような,データがないことを示す特別な値(欠損値)になります。よいモデル作成、良い分析するときに、欠損値処理が必要です。欠損値原因により、処理方法が異なります。たとえば、欠損値が50%を超える場はデータを削除するはずです。
欠損値が含まれるデータを扱う上で複数問題があります。まず、統計計算ができなくなります。また、分析の結果はバイアスが生じます。モデル作成する場合は欠損値を処理しないといけません。
欠損値のタイプ
欠損値が生じる要因として,大きく分けて3つが考えられています。
2. MCAR (Missing Completely At Random)
MCAR とは,いわゆる欠損値が完全にランダムに生じているようなケースである。データになんにも依存していなくて,ほんと気まぐれ,という感じ。これは一番わかりやすい欠損のタイプです。
3. MAR (Missing At Random)
MARとは,データが,測定されている値に依存して欠損する。MCAR と聞いた感じが似ているかもしれないが,MCAR よりもずっと制約が弱まっています。MCAR と違うのは,他の変数と欠損値の有無とが関係することを許容しています。
4. MNAR (Missing Not At Random)
MNAR とは,分析に含まれる他の変数を統制した後でも,欠損値の有無が欠損値を持つ変数自身と関係を持つケースを示している。
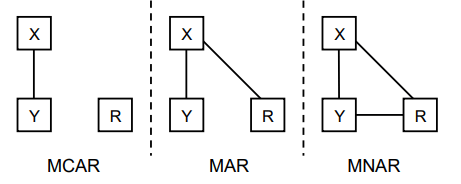
MCAR, MAR, MNAR の概念図
Y が欠損値のある変数。
R が欠損値の有無をコーディングした確率変数。
X は分析に含まれるその他の変数。
欠損に対するアプローチ
1.欠損値の除去
2.代入法(imputation)
3.不完全データとして尤度を記述する方法
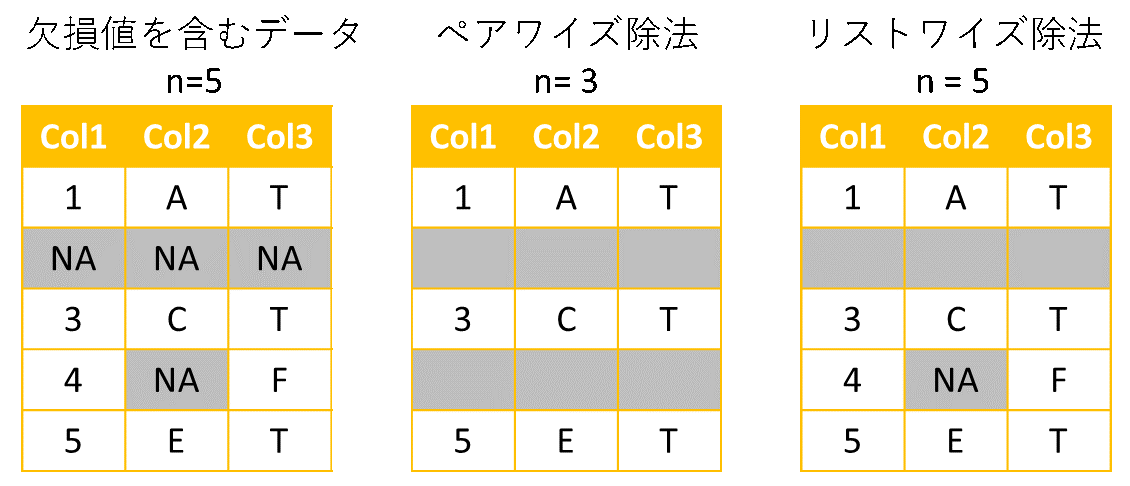
5. 欠損値の削除
データとして扱う変数のいずれかに欠損があるケースをすべての計算から除去し,残りのケースで解析を行う のがリストワイズ除去法 (listwise deletion) である。ひとつひとつの計算について,その計算で扱う変数のいずれかに欠損があるケースをその計算から(だけ)除去するのがペアワイズ除去法 (pairwise deletion) である。
6. 代入法(imputation)
代入法とは、欠損した数値データの情報を失わずに補完する方法を考えます。scikit-learnのパッケージは欠損値補完の前処理に対するサポートも充実しています。scikit-learnには2つの方法があります。
6.1 一変量代入法(Univariate feature Imputation)
一変量代入法はi番目のフィーチャーディメンションの値を、そのフィーチャーディメンションの非欠損値のみを使用して代入します。欠損値部分は列の平均値、中央値、最頻値で埋められます。
6.2 多変量代入法(Multivariate feature imputation)
多変量代入法は 全てのフィーチャーディメンションの値を非欠損値のみを使用して代入します。
代入法の実験
データ作成
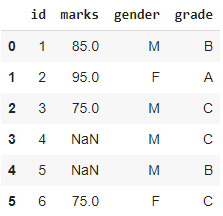
import pandas as pd import numpy as np students = [[1, 85, 'M', 'B'], [2, 95, 'F', 'A'], [3, 75, None,'C'], [4, np.NaN, 'M', 'C'], [5, np.NaN, 'M', 'B'], [6, 75, 'F', 'C']] df = pd.DataFrame(students) df.columns = ['id', 'marks', 'gender', 'grade'] df
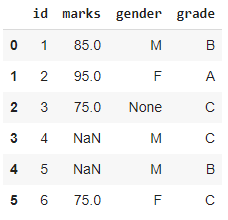
数字の欠損値代入
平均値 strategy=’mean’
中央値 strategy=’median’
最頻値 strategy=’most_frequent’
特定値 strategy=’constant’
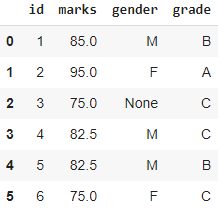
from sklearn.impute import SimpleImputer # Mean inputation df2 = df.copy() imputer = SimpleImputer(missing_values=np.NaN, strategy='mean') df2.marks = imputer.fit_transform(df2['marks'].values.reshape(-1,1))[:,0] df2
カテゴリーの欠損値代入
最頻値 strategy=’most_frequent’
特定値 strategy=’constant’
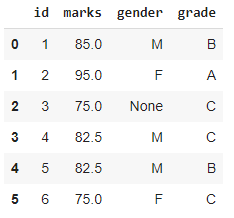
from sklearn.impute import SimpleImputer # Category inputation df6 = df.copy() imputer = SimpleImputer(missing_values=None, strategy='most_frequent') df3.gender = imputer.fit_transform(df3['gender'].values.reshape(-1,1))[:,0] df3
多変量代入法
from sklearn.experimental import enable_iterative_imputer from sklearn.impute import IterativeImputer # Multivariate feature imputation df4 = df.copy() imputer = IterativeImputer(max_iter=10, random_state=10) df4.marks = imputer.fit_transform(df4['marks'].values.reshape(-1,1))[:,0] df4

担当者:HM
香川県高松市出身 データ分析にて、博士(理学)を取得後、自動車メーカー会社にてデータ分析に関わる。その後コンサルティングファームでデータ分析プロジェクトを歴任後独立 気が付けばデータ分析プロジェクトだけで50以上担当
理化学研究所にて研究員を拝命中 応用数理学会所属