
目次:
1. 概要
2. 主な貢献
3. インコンテキスト学習のスケーリング 3.1 機械翻訳(MT)
3.2. 要約 3.3. 計画:ロジスティクス分野
3.4. 報酬モデリング:コード検証のインコンテキスト学習
4. ヒューマンライターの合理を使用しない多ショット学習
4.1. 問題解決:Hendrycks MATH & GSM8K 4.2. 質問応答:Google-Proof QA(GPQA)
4.3. アルゴリズムおよび象徴的推論:Big-Bench Hard
5. 多ショットインコンテキスト学習の分析
5.1. 多ショットICLで事前学習バイアスを克服
5.2. 非自然言語タスクの学習
5.3. 多ショットICLは例の順序に敏感か?
5.4. NLLはICLのパフォーマンスを予測できないかもしれない 6. 実験
7. まとめ
| タイトル:Many-Shot In-Context Learning URL:https://arxiv.org/abs/2404.11018 所属:Google DeepMind |
1.概要
大規模言語モデル(LLM)は、数ショットインコンテキスト学習(ICL)に優れており、推論時に提供されるいくつかの例から学習し、重みの更新なしにタスクを学習します。新しく拡張されたコンテキストウィンドウにより、数百または数千の例を使用した多ショットICLを調査することが可能になりました。数ショットから多ショットに移行することで、さまざまな生成タスクおよび判別タスクで大幅なパフォーマンス向上が見られました。しかし、多ショットICLは、人間が生成した出力の量によってボトルネックが発生する可能性があります。この制限を軽減するために、「強化ICL」と「無監督ICL」の2つの新しい設定を探ります。強化ICLは、人間の合理の代わりにモデル生成の連鎖思考合理を使用し、無監督ICLは合理をプロンプトから完全に削除し、ドメイン固有の入力のみをモデルに提示します。どちらの設定も多ショット領域で効果的であり、特に複雑な推論タスクで効果的であることがわかりました。
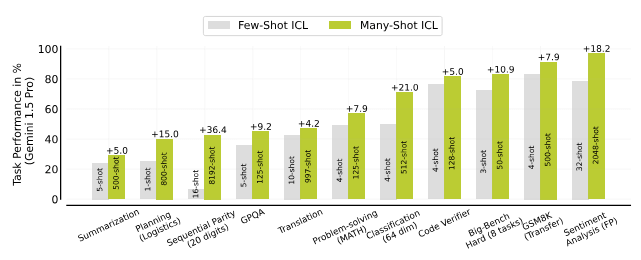
複数のタスクにわたる多数ショット(Many-shot ICL)と少数ショット(Few-shot ICL)のインコンテキスト学習 (ICL)。 メニーショット学習は、数ショット ICL よりも一貫したパフォーマンスの向上を示します。
2.主な貢献
- インコンテキスト学習のスケーリング: 多くのタスクでインコンテキスト例のスケーリングがLLMのパフォーマンスに与える影響を体系的に評価しました。数ショットから多ショット学習への移行で大幅なパフォーマンス向上が見られました。
- 強化および無監督ICL: モデル生成の合理または問題のみを使用することで、多ショット学習の人間生成データへの依存を減らすことができることを発見しました。
- ICLの分析: 多ショットICLが事前学習バイアスを克服し、数ショットICLでは困難な非自然言語予測タスクを学習できることを発見しました。
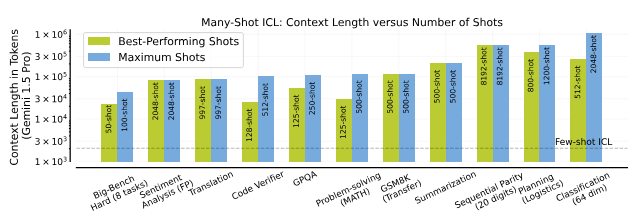
最高のパフォーマンスを発揮するためのコンテキストの長さと、各タスクでテストされたショットの最大数。
3.インコンテキスト学習のスケーリング
3.1. 機械翻訳(MT)
英語から低リソースのターゲット言語への機械翻訳で、多ショットICLがパフォーマンスを向上させることを確認しました。特に、クルド語やタミル語の翻訳で多ショットICLがGoogle Translateを上回りました。
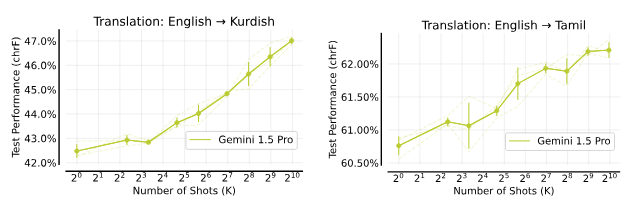
機械翻訳(MT)。推論時にコンテキスト例として提供されるMTペアの数を増やすと、テストパフォーマンスはほぼ単調に向上します。どちらの場合も、Gemini 1.5 ProはGoogle翻訳を上回り、Google翻訳はクルド語で40%、タミル語で56%のchRFを取得しました。コンテキストの長さに関しては、997ショットのプロンプトはクルド語への翻訳では85.3Kトークン、タミル語への翻訳では95.3Kトークンに対応します。
3.2. 要約
XSumタスクでの多ショットICLは、専門の要約モデル(PEGASUSやmT5)とほぼ同等のパフォーマンスを達成しました。XSumのパフォーマンスは50ショットを超えると低下しましたが、XLSumのパフォーマンスは一貫して向上しました。
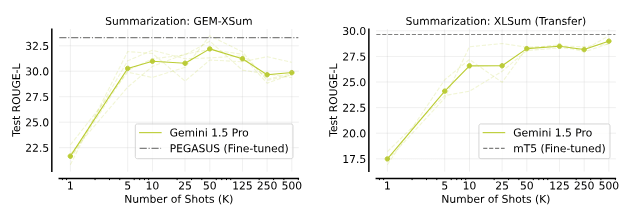
要約。XSumの開発セットから(ニュース記事、要約)のペアをコンテキスト例として増やすと、XSumのパフォーマンスは50ショットまで向上し、その後は低下します。対照的に、XLSumのパフォーマンスは通常、XSumのショット数が増えるにつれて向上します。500ショットのプロンプトは205Kトークンに対応します。
3.3. 計画:ロジスティクス分野
LLMの計画生成能力を評価し、多ショットICLが計画成功率を大幅に向上させることを確認しました。
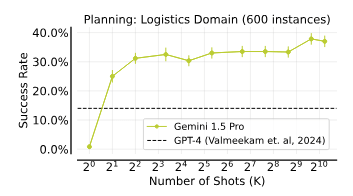
コンテキスト内プランニング。成功率は最大10ショット(37Kトークン)で急速に向上し、その後400ショットまで飽和し、800ショットで突然パフォーマンスが向上します。
3.4. 報酬モデリング:コード検証のインコンテキスト学習
GSM8Kコードソリューションの正確性を検証するために、インコンテキスト学習を使用して検証モデルを学習しました。多ショットプロンプトにより、検証モデルの精度が向上しました。
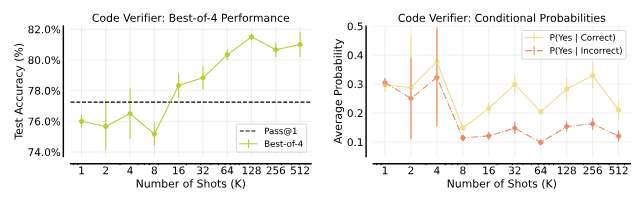
GSM8Kコードソリューションの正確性をチェックするためのコンテキスト内での検証器の学習。エラーバーは3つのシードの平均に対する標準誤差を示しています。2ショットプロンプトの例です。ベストオブNの精度。(左) 200のGSM8Kテスト問題において、検証器スコアに基づくトップランクのコードソリューション(4つのソリューションの中から)の平均精度。128ショットのベストオブ4の選択により、Gemini 1.0 ProモデルのPass@1精度77.25%とPass@4精度90%のギャップを埋めます。検証器の信頼度。(右) テスト問題における正解と不正解のソリューション全体にわたる、検証器からのYesトークンIP(Yes)の条件付き確率の平均。
4.ヒューマンライターの合理を使用しない多ショット学習
4.1. 問題解決:Hendrycks MATH & GSM8K
Reinforced ICLとUnsupervised ICLの両方が、問題解決ドメインで人間が生成した合理を使用するICLよりも優れていることがわかりました。多ショットICLはMATHプロンプトを使用してGSM8Kでも高いパフォーマンスを発揮しました。
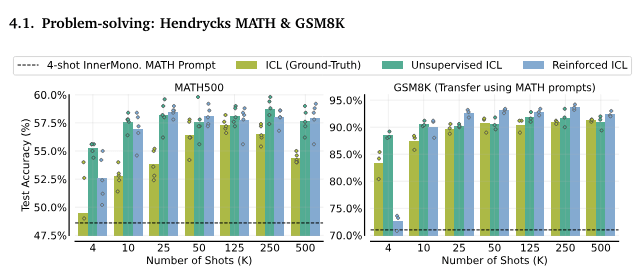
多ショットの強化ICLおよび教師なしICLは、問題解決において一般的にグランドトゥルースMATH解を用いたICLよりも優れています。MATH。(左) 棒グラフは、MATH500テストセットにおける5つのランダムシードの平均性能を示しています。各ランダムシード(ドットで示される)は、プロンプト内の異なる問題のサブセットとグランドトゥルースまたはモデル生成の解(もしあれば)に対応しています。GSM8Kへの転送。(右) MATHから得られたプロンプトは、500の問題を含むGSM8Kテストスプリットにうまく転送されます。多ショットICLを用いた我々の結果は、MATH500で55.7%、GSM8Kで90.6%のテスト精度を得た4ショットMinervaプロンプトを上回りました。
4.2. 質問応答:Google-Proof QA(GPQA)
GPQAのテストでは、多ショットプロンプトがパフォーマンスを向上させました。Reinforced ICLが特に優れており、125ショットプロンプトで最高のパフォーマンスを達成しました。
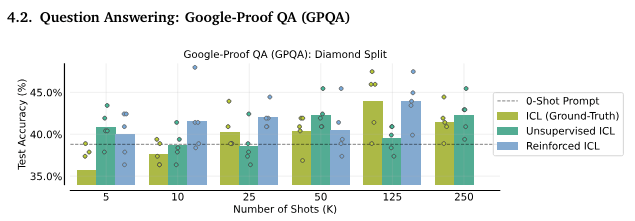
GPQAのための多ショット強化ICLおよび教師なしICL。強化ICLの推論を生成するために使用され、教師なしICLのプロンプトに追加されるベースラインのゼロショットプロンプトは、38.8%の性能を達成しました。125ショットのプロンプトを使用した場合、グランドトゥルースまたはモデル生成の推論の両方で、Claude-3 Sonnetが得た40.4%を上回る平均テスト精度を達成しました。ショット数を変えると、教師なしICLはゼロショットプロンプトと同等またはそれ以上の性能を示し、強化ICLは一貫してそれを上回る性能を示します。
4.3. アルゴリズムおよび象徴的推論:Big-Bench Hard
Reinforced ICLは、標準の3ショットプロンプトよりも優れたパフォーマンスを示しました。多くのタスクで、Reinforced ICLはモデル生成の合理を使用してパフォーマンスを向上させました。
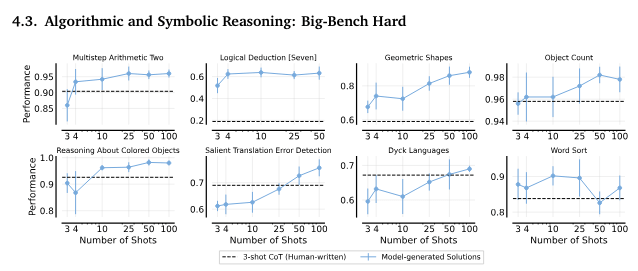
BIG-Bench Hard。強化ICLのショット数に対する性能(5つのランダムシードの平均)。エラーバーは標準偏差を示しています。強化ICLは全てのタスクにおいて人間が書いた思考の連鎖プロンプトを上回りました。タスク全体の平均では、人間が書いたプロンプトを使用した思考の連鎖プロンプトは成功率72.1%ですが、強化ICLは83%の成功率を達成しました。
5.多ショットインコンテキスト学習の分析
5.1. 多ショットICLで事前学習バイアスを克服
多ショットICLは、事前学習バイアスを克服し、ラベルの入れ替えや抽象ラベルを使用しても高いパフォーマンスを発揮しました。
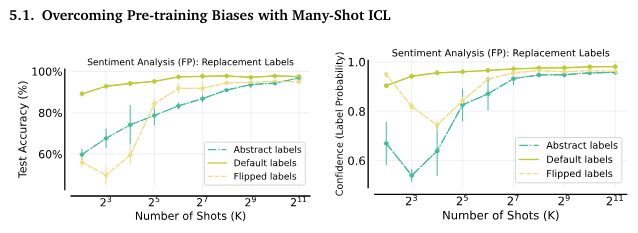
多ショットICLで事前学習のバイアスを克服する方法。(左) 多ショットICLはラベルの逆転を克服します。感情分析のテスト精度は、訓練ショットが増えると通常向上します。反転されたラベルや抽象的なラベルも最終的にはデフォルトラベルの性能に近づきます。(右) バイアス克服時の信頼度の変化。反転されたラベルや抽象的なラベルの場合、予測された感情ラベルに対するモデルの信頼度は最初に低下し、その後、訓練ショットが増えると急激に増加し、同様の値に達します。これは事前学習のバイアスを克服する期間があることを示唆しています。
5.2. 非自然言語タスクの学習
高次元の線形分類や順列パリティなどの抽象的な数学関数の学習において、多ショットICLが優れたパフォーマンスを示しました。
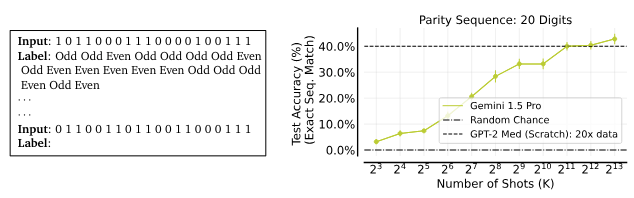
コンテキスト内での逐次パリティ関数の学習。3つのシードの平均に基づく、200の未見入力に対するテスト精度を報告します。エラーバーは平均の標準誤差を示しています。タスクプロンプト。(左) 20桁の逐次パリティ関数の入力と出力ラベルを含むプロンプトの例。テスト精度。(右) 多ショットICLの性能はショット数が増えるにつれてほぼ単調に向上し、20倍のデータで1エポックから訓練されたGPT-2 Mediumサイズのトランスフォーマーの性能を上回ります。
5.3. 多ショットICLは例の順序に敏感か?
MATHタスクで50ショットの例の順序を変更することで、パフォーマンスが大きく変動することを確認しました。これは多ショットICLでも例の順序が重要であることを示唆しています。
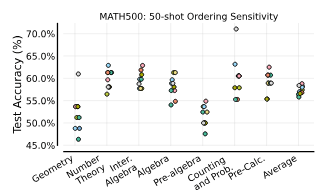
多ショットの例の順序に対する感度。各色のデータポイントは、Gemini 1.5 Proに提供された50のコンテキスト内例の異なるランダムな順序を表しています。
5.4. NLLはICLのパフォーマンスを予測できないかもしれない
NLL(ネガティブ対数尤度)は、多ショットICLの最終パフォーマンスを予測する信頼性のある指標ではないことがわかりました。これは、問題解決ドメインでは正確な合理のパスが多数存在するためです。
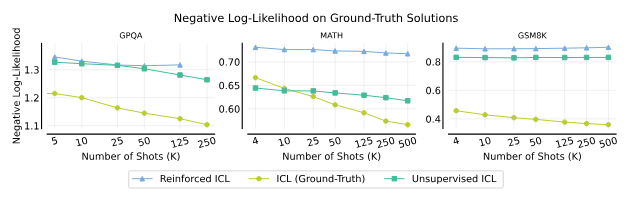
ショット数に対するNegative log-likelihood(NLL)。GPQA、MATH、およびGSM8Kのテストセットに対するNLLを示します。GPQAとMATHでは、強化ICLと教師なしICLの質問はそれぞれのデータセットのトレーニング部分から取られます。GSM8Kは転送設定で研究し、質問はMATHから取られます。ICLと強化ICLのNLL数値は、教師なしICLと異なるプロンプト形式を使用しているため、直接比較できないことに注意してください。
6.実験
Hendrycks 数字問題のデータセットで実験してみます。(https://github.com/hendrycks/math)
Gemini(無料版)で実験しました。
代数の問題:
プロンプト:
| — [質問と回答例] — “problem”: “If $A=2+i$, $O=-4$, $P=-i$, and $S=2+4i$, find $A-O+P+S$.”, What is the solution of this problem? |
正解回答は 8+4i です。
0ショット、5ショット、10ショット、15ショットを実行しました。
0ショットの結果:[不正解]

5ショットの結果:[不正解]

10ショットの結果:[不正解]

15ショットの結果:[正解]
「5ショット」と「10ショット」は正しくない回答です。「15ショット」が正しい回答です。

7.まとめ
多ショットインコンテキスト学習の可能性を調査し、多くのタスクで数ショットICLに対して大幅なパフォーマンス向上を示しました。特に、強化ICLと無監督ICLの新しい設定が、人間が生成した合理を必要としない問題解決ドメインで有効であることを確認しました。また、多ショット学習が事前学習バイアスを克服し、非自然言語タスクを学習できることを発見しました。

担当者:KW
バンコクのタイ出身 データサイエンティスト
製造、マーケティング、財務、AI研究などの様々な業界にPSI生産管理、在庫予測・最適化分析、顧客ロイヤルティ分析、センチメント分析、SaaS、PaaS、IaaS、AI at the Edge の環境構築などのスペシャリスト