
前回はkaggleコンペの「Home Credit Default Risk 債務不履行の予測」の1位の解析手法を話しました。今回は「ASHRAE 消費エネルギー予測」の1位の解析手法をまとめたいと思います。内容が長いなので、2つの記事に分けました。
関連記事:「メルカリにおける値段推定」「Cdiscount 画像分類」「Home Credit Default Risk 債務不履行の予測」
目次
1. ASHRAE 消費エネルギー予測のコンペの概要
___1.1 コンペの概要
___1.2 データセットの概要
___1.3 データの理解
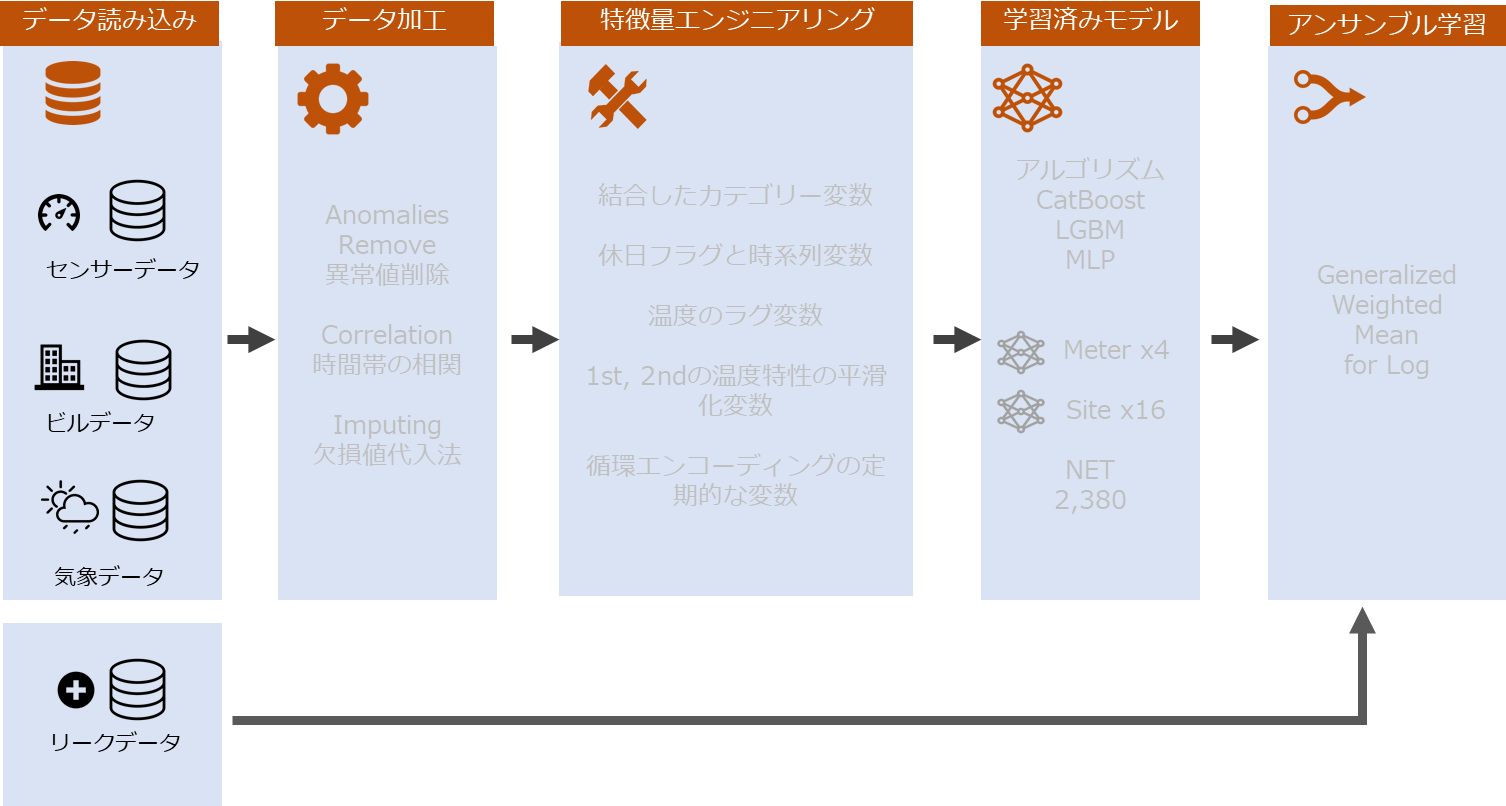
2. 1位の解析手法
___2.1 前処理
___2.2 フィギュア・エンジニアリング
___2.3 モデル
1. ASHRAE 消費エネルギー予測のコンペの概要
1.1 コンペの概要

ビルでの省エネの施策を実施した場合の効果を見積もるために、冷水、電気、温水、蒸気などのセンサーデータに基づいて、エネルギー使用量を予測するコンペでした。
賞金: 1位 10,000米ドル、2位7,000米ドル、3位5,000米ドル、4位2,000米ドル、5位1,000米ドル
期間: 2019/10/16 ~ 2019/12/20
参加チーム数:7,190
評価:評価指標はRMSLE(Root Mean Squared Logarithmic Error)
RMSEとか平均平方二乗誤差といいます。すべての誤差の平方根の平均です。連続値の値でどれぐらい離れているかを平均を取り、平方根で評価します。
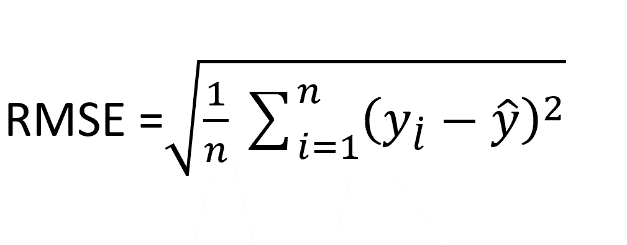
詳細: RMSLE を用いた評価指標
1.2 データセットの概要
train.csv
学習データで、各センサーの時間、量数のデータ(ビルのデータに紐付ける)
building_meta.csv
各ビル、活動の分類、建物の面積、築年、建物の階数のデータ(天気のデータとセンサーのデータに紐付ける)
weather_[train/test].csv
学習とテストのデータで、サイトに近い気象データ。温度、雲量、露点温度、降水量、海面気圧、風向き、風速のデータ。(ビルのデータに紐付ける)
test.csv
正しい順序への予測ための行ID、ビルID、センサーID、期間
sample_submission.csv
発行のサンプルデータ
ER図
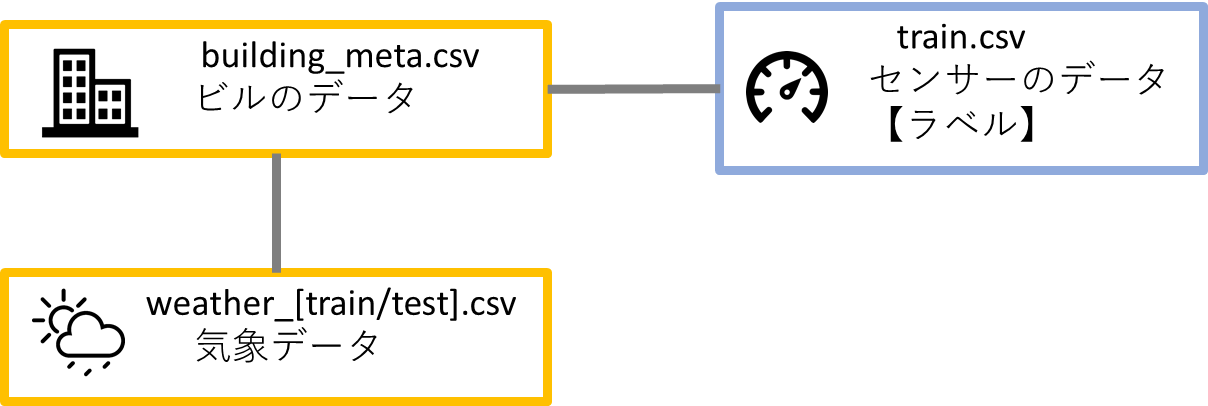
データのリレーションと特徴量は複雑ではありません。
1.3 データの理解
ライブラリのインストール
import numpy as np
import pandas as pd
import matplotlib
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
import gc
warnings.simplefilter('ignore')
matplotlib.rcParams['figure.dpi'] = 100
sns.set()
%matplotlib inline全てのcsvファイルを読み込んで、データフレームを作成します。
# データ読み込み
building = pd.read_csv('../input/ashrae-energy-prediction/building_metadata.csv')
weather_train = pd.read_csv('../input/ashrae-energy-prediction/weather_train.csv')
weather_test = pd.read_csv('../input/ashrae-energy-prediction/weather_test.csv')
train = pd.read_csv('../input/ashrae-energy-prediction/train.csv')
test = pd.read_csv('../input/ashrae-energy-prediction/test.csv')# データ結合
train = train.merge(building, on='building_id', how='left') test = test.merge(building, on='building_id', how='left') train = train.merge(weather_train, on=['site_id', 'timestamp'], how='left') test = test.merge(weather_test, on=['site_id', 'timestamp'], how='left') del weather_train, weather_test,building gc.collect();
#省メモリ
# Saving some memory
d_types = {'building_id': np.int16,
'meter': np.int8,
'site_id': np.int8,
'primary_use': 'category',
'square_feet': np.int32,
'year_built': np.float16,
'floor_count': np.float16,
'air_temperature': np.float32,
'cloud_coverage': np.float16,
'dew_temperature': np.float32,
'precip_depth_1_hr': np.float16,
'sea_level_pressure': np.float32,
'wind_direction': np.float16,
'wind_speed': np.float32}
for feature in d_types:
train[feature] = train[feature].astype(d_types[feature])
test[feature] = test[feature].astype(d_types[feature])
train["timestamp"] = pd.to_datetime(train["timestamp"])
test["timestamp"] = pd.to_datetime(test["timestamp"])
gc.collect();#欠損値の確認
train_data = (train.count() / len(train)).drop('meter_reading').sort_values().values
ind = np.arange(len(train_data))
width = 0.35
fig, axes = plt.subplots(1,1,figsize=(14, 6), dpi=100)
tr = axes.bar(ind, train_data, width, color='royalblue')
test_data = (test.count() / len(test)).drop('row_id').sort_values().values
tt = axes.bar(ind+width, test_data, width, color='seagreen')
axes.set_ylabel('Amount of data available');
axes.set_xticks(ind + width / 2)
axes.set_xticklabels((train.count() / len(train)).drop('meter_reading').sort_values().index, rotation=40)
axes.legend([tr, tt], ['Train', 'Test']);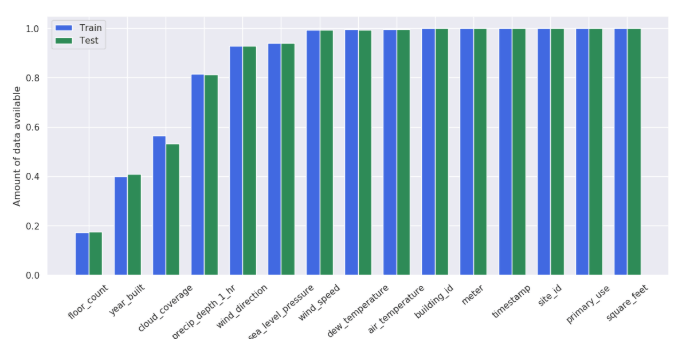
# 日別のデータ件数の確認
学習データの件数は凸凹の状態になっていますが、テストデータの件数は平たいです。
fig, axes = plt.subplots(1, 1, figsize=(14, 6))
train['timestamp'].dt.floor('d').value_counts().sort_index().plot(ax=axes).set_xlabel('Date', fontsize=14);
test['timestamp'].dt.floor('d').value_counts().sort_index().plot(ax=axes).set_ylabel('Number of observations', fontsize=14);
axes.set_title('Number of observations by day', fontsize=16);
axes.legend(['Train', 'Test']);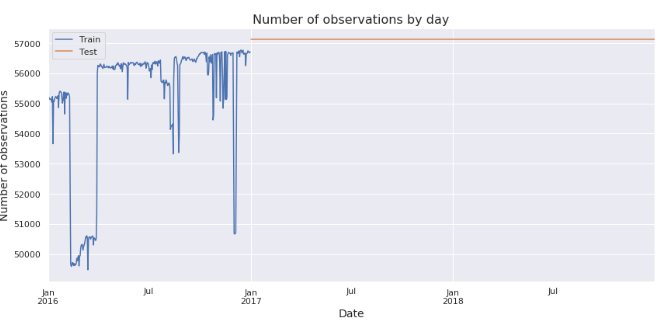
# meter id別のmeterの平均
meter idは0: electricity, 1: chilledwater, 2: steam..になっています。
2: steam, hotwaterは一番費用が高いです。
train_data = train['meter'].value_counts(dropna=False, normalize=True).sort_index().values
ind = np.arange(len(train_data))
width = 0.35
fig, axes = plt.subplots(1,1,figsize=(14, 6), dpi=100)
tr = axes.bar(ind, train_data, width, color='royalblue')
test_data = test['meter'].value_counts(dropna=False, normalize=True).sort_index().values
tt = axes.bar(ind+width, test_data, width, color='seagreen')
axes.set_ylabel('Normalized number of observations');
axes.set_xlabel('meter type');
axes.set_xticks(ind + width / 2)
axes.set_xticklabels(train['meter'].value_counts().sort_index().index, rotation=0)
axes2 = axes.twinx()
mr = axes2.plot(ind, train[['meter', 'meter_reading']].groupby('meter')['meter_reading'].mean().sort_index().values, 'D-', color='tab:orange', label='Mean meter reading');
axes2.grid(False);
axes2.tick_params(axis='y', labelcolor='tab:orange');
axes2.set_ylabel('Mean meter reading by meter type', color='tab:orange');
axes.legend([tr, tt], ['Train', 'Test'], facecolor='white');
axes2.legend(loc=5, facecolor='white');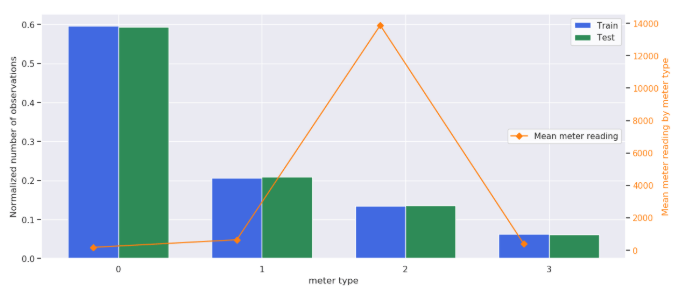
#日別と時間別のmeter平均
3月から6月までmeter平均が高かったです。また、11月はスパイクの状態になっています。
fig, axes = plt.subplots(1, 1, figsize=(14, 6), dpi=100)
train[['timestamp', 'meter_reading']].set_index('timestamp').resample('H').mean()['meter_reading'].plot(ax=axes, label='By hour', alpha=0.8).set_ylabel('Meter reading', fontsize=14);
train[['timestamp', 'meter_reading']].set_index('timestamp').resample('D').mean()['meter_reading'].plot(ax=axes, label='By day', alpha=1).set_ylabel('Meter reading', fontsize=14);
axes.set_title('Mean Meter reading by hour and day', fontsize=16);
axes.legend();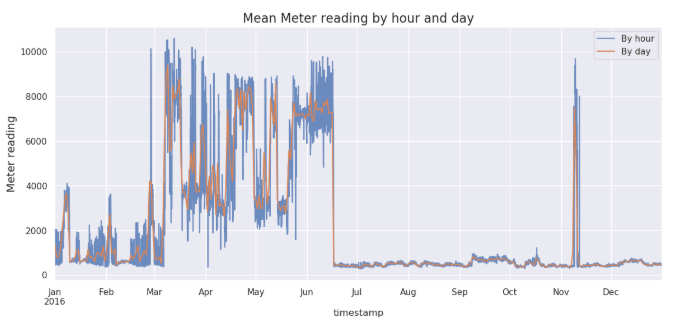
#site別のmeter平均
詳細をみると、site_id 0は3月からはじまるそうです。Site_id 13は全体の平均値と同じパターンです。
fig, axes = plt.subplots(8,2,figsize=(14, 30), dpi=100)
for i in range(train['site_id'].nunique()):
train[train['site_id'] == i][['timestamp', 'meter_reading']].set_index('timestamp').resample('H').mean()['meter_reading'].plot(ax=axes[i%8][i//8], alpha=0.8, label='By hour', color='tab:blue').set_ylabel('Mean meter reading', fontsize=13);
train[train['site_id'] == i][['timestamp', 'meter_reading']].set_index('timestamp').resample('D').mean()['meter_reading'].plot(ax=axes[i%8][i//8], alpha=1, label='By day', color='tab:orange').set_xlabel('');
axes[i%8][i//8].legend();
axes[i%8][i//8].set_title('site_id {}'.format(i), fontsize=13);
plt.subplots_adjust(hspace=0.45)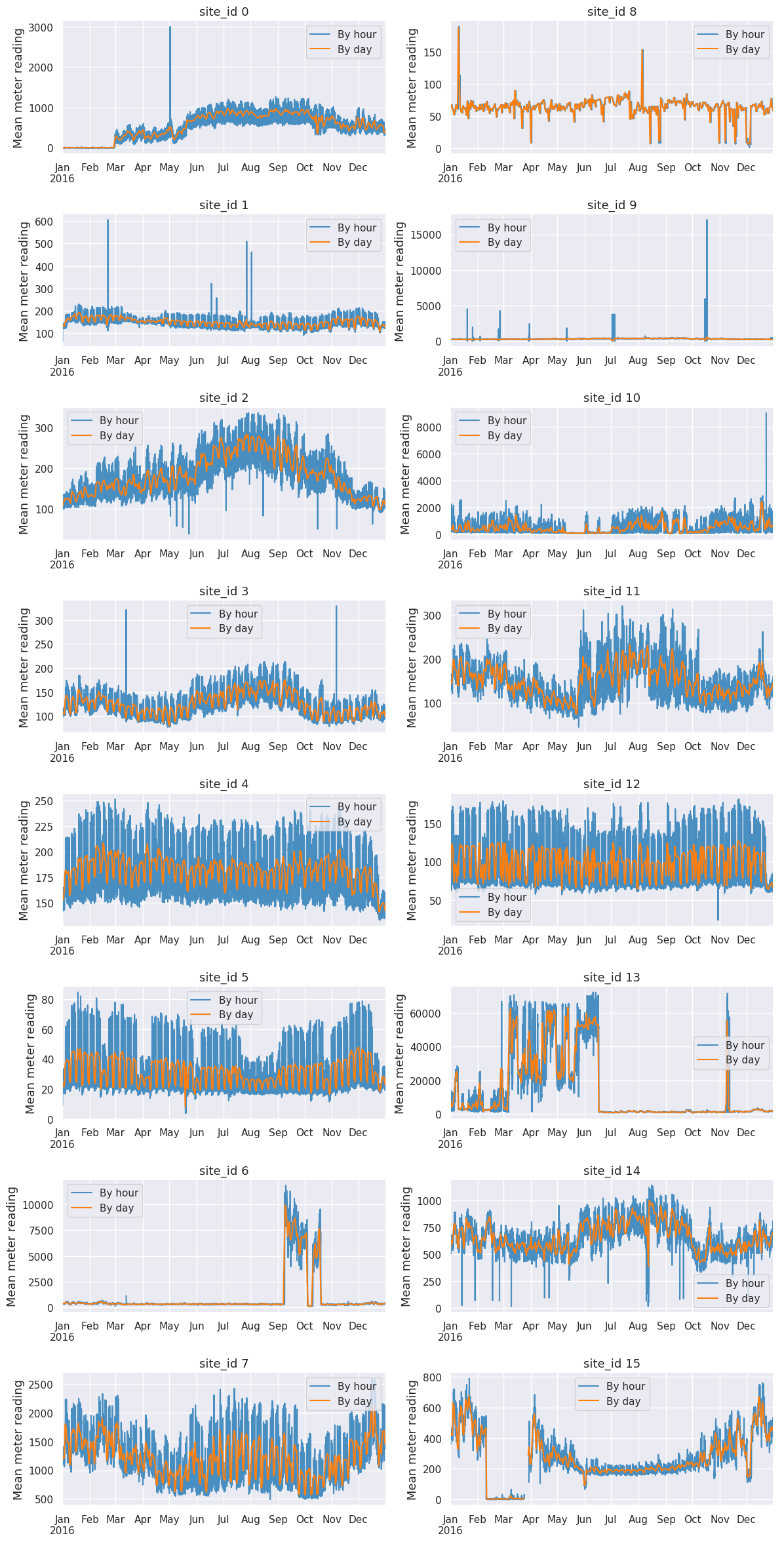
#ではsite_id 13のデータを確認しましょう。
primary_use別のmeter平均
site_id 13 の primary_use:Educationは全体の平均と同じパターンになっています。
fig, axes = plt.subplots(8,2,figsize=(14, 30), dpi=100)
for i, use in enumerate(train['primary_use'].value_counts().index.to_list()):
try:
train[(train['site_id'] == 13) & (train['primary_use'] == use)][['timestamp', 'meter_reading']].set_index('timestamp').resample('H').mean()['meter_reading'].plot(ax=axes[i%8][i//8], alpha=0.8, label='By hour', color='tab:blue').set_ylabel('Mean meter reading', fontsize=13);
train[(train['site_id'] == 13) & (train['primary_use'] == use)][['timestamp', 'meter_reading']].set_index('timestamp').resample('D').mean()['meter_reading'].plot(ax=axes[i%8][i//8], alpha=1, label='By day', color='tab:orange').set_xlabel('');
axes[i%8][i//8].legend();
except TypeError:
pass
axes[i%8][i//8].set_title(use, fontsize=13);
plt.subplots_adjust(hspace=0.45)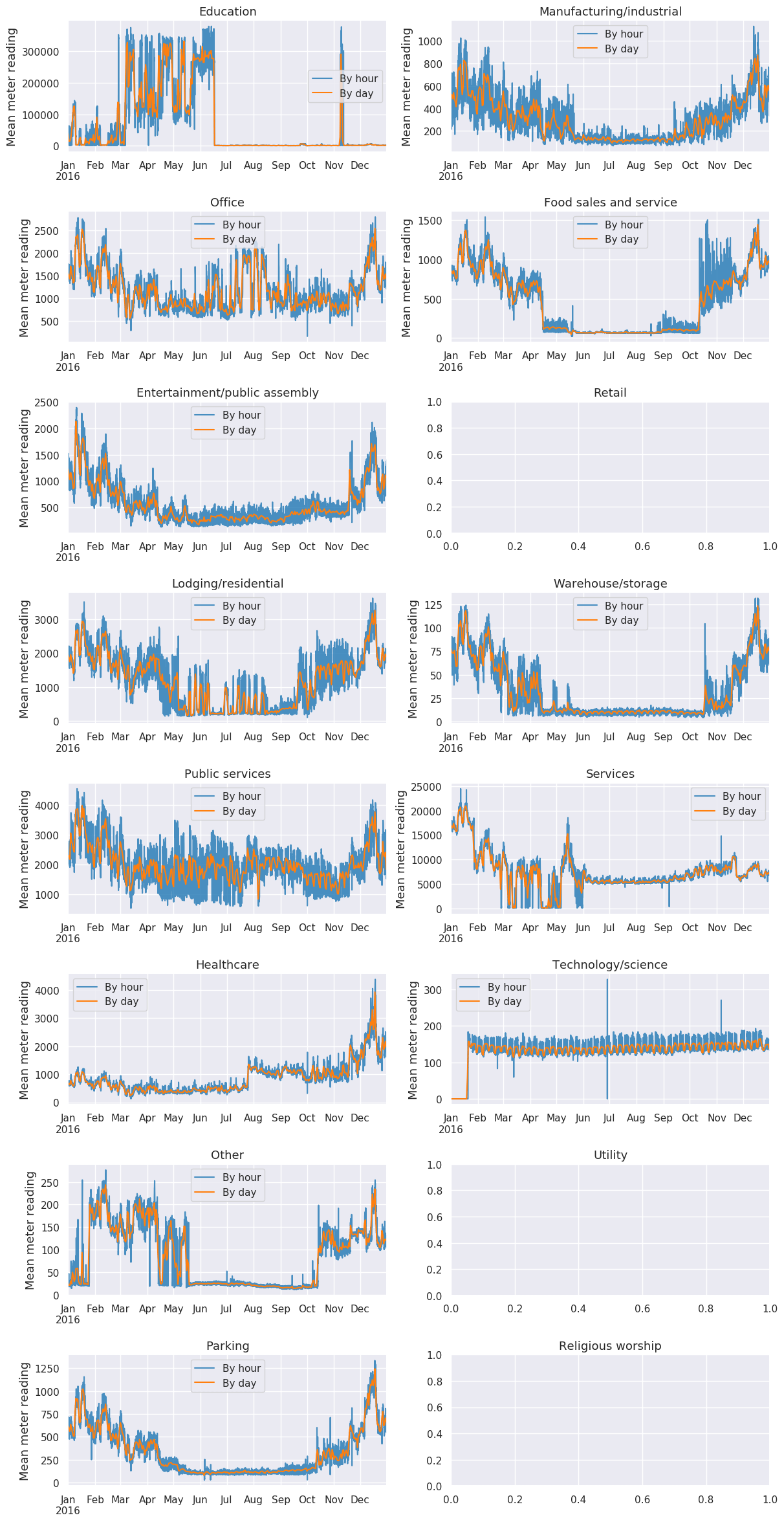
# primary_use
利用項目別の値を見ると、Education と Serviceの平均値は高いです。
train_data = train['primary_use'].value_counts(dropna=False, normalize=True).sort_index().values
ind = np.arange(len(train_data))
width = 0.35
fig, axes = plt.subplots(1,1,figsize=(14, 6), dpi=100)
tr = axes.bar(ind, train_data, width, color='royalblue')
test_data = test['primary_use'].value_counts(dropna=False, normalize=True).sort_index().values
tt = axes.bar(ind+width, test_data, width, color='seagreen')
axes.set_ylabel('Normalized number of observations');
axes.set_xlabel('primary_use');
axes.set_xticks(ind + width / 2)
axes.set_xticklabels(train['primary_use'].value_counts().sort_index().index, rotation=90)
axes2 = axes.twinx()
mr = axes2.plot(ind, train[['primary_use', 'meter_reading']].groupby('primary_use')['meter_reading'].mean().sort_index().values, 'D-', color='tab:orange', label='Mean meter reading');
axes2.grid(False);
axes2.tick_params(axis='y', labelcolor='tab:orange');
axes2.set_ylabel('Mean meter reading by primary_use', color='tab:orange');
axes.legend([tr, tt], ['Train', 'Test'], facecolor='white');
axes2.legend(loc=5, facecolor='white');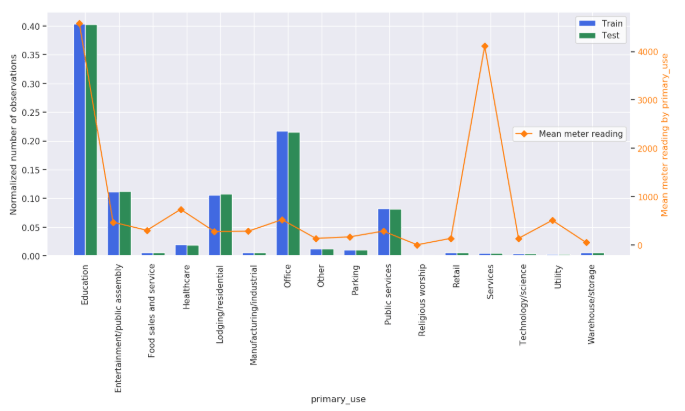
#air_temperature
気温の推移をみると、1月は一番低いて7月は一番高いになっています。
fig, axes = plt.subplots(1,1,figsize=(14, 6), dpi=100)
train[['timestamp', 'air_temperature']].set_index('timestamp').resample('H').mean()['air_temperature'].plot(ax=axes, alpha=0.8, label='By hour', color='tab:blue').set_ylabel('Mean temperature', fontsize=14);
test[['timestamp', 'air_temperature']].set_index('timestamp').resample('H').mean()['air_temperature'].plot(ax=axes, alpha=0.8, color='tab:blue', label='');
train[['timestamp', 'air_temperature']].set_index('timestamp').resample('D').mean()['air_temperature'].plot(ax=axes, alpha=1, label='By day', color='tab:orange');
test[['timestamp', 'air_temperature']].set_index('timestamp').resample('D').mean()['air_temperature'].plot(ax=axes, alpha=1, color='tab:orange', label='');
axes.legend();
axes.text(train['timestamp'].iloc[9000000], -3, 'Train', fontsize=16);
axes.text(test['timestamp'].iloc[29400000], 30, 'Test', fontsize=16);
axes.axvspan(test['timestamp'].min(), test['timestamp'].max(), facecolor='green', alpha=0.2);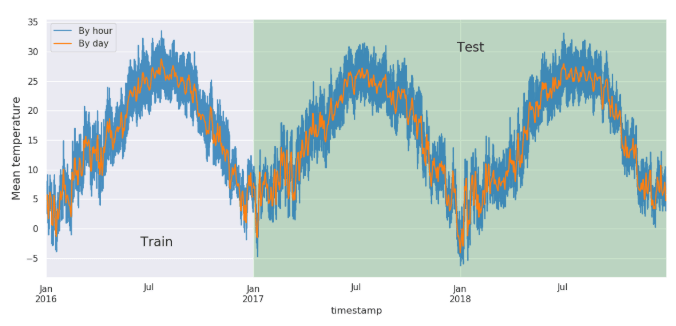
# cloud_coverage
雲量のOkata値は8.になると、平均値は高いそうです。
雲量のOkataの詳細:Okta
fig, axes = plt.subplots(1, 2, figsize=(14, 6), dpi=100)
train['cloud_coverage'].value_counts(dropna=False, normalize=True).sort_index().plot(kind='bar', rot=0, ax=axes[0]).set_xlabel('cloud_coverage value');
test['cloud_coverage'].value_counts(dropna=False, normalize=True).sort_index().plot(kind='bar', rot=0, ax=axes[1]).set_xlabel('cloud_coverage values');
axes[0].set_title('Distribution in train', fontsize=14);
axes[1].set_title('Distribution in test', fontsize=14);
ax2 = axes[0].twinx()
train[['cloud_coverage', 'meter_reading']].replace(np.nan, 'nan').groupby('cloud_coverage')['meter_reading'].mean().plot(ax=ax2, style='D-', grid=False, color='tab:orange');
ax2.tick_params(axis='y', labelcolor='tab:orange');
ax2.set_ylabel('Mean meter reading', color='tab:orange', fontsize=14);
ax2.set_xticklabels(train['cloud_coverage'].value_counts(dropna=False).sort_index().index)
plt.subplots_adjust(wspace=0.4);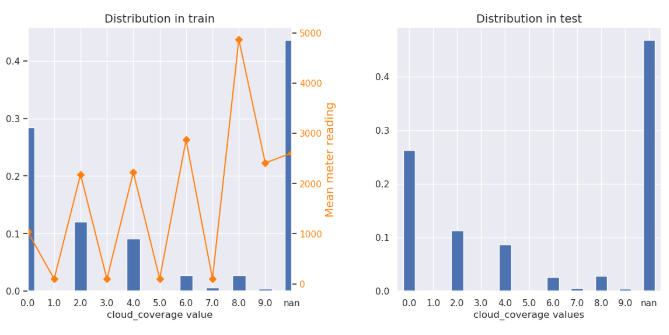
dew_temperature
降水量は気温と相関があるそうです。7月は降水量が一番高いです。
fig, axes = plt.subplots(1,1,figsize=(14, 6), dpi=100)
train[['timestamp', 'dew_temperature']].set_index('timestamp').resample('H').mean()['dew_temperature'].plot(ax=axes, alpha=0.8, label='By hour', color='tab:blue').set_ylabel('Mean dew temperature', fontsize=14);
test[['timestamp', 'dew_temperature']].set_index('timestamp').resample('H').mean()['dew_temperature'].plot(ax=axes, alpha=0.8, color='tab:blue', label='');
train[['timestamp', 'dew_temperature']].set_index('timestamp').resample('D').mean()['dew_temperature'].plot(ax=axes, alpha=1, label='By day', color='tab:orange');
test[['timestamp', 'dew_temperature']].set_index('timestamp').resample('D').mean()['dew_temperature'].plot(ax=axes, alpha=1, color='tab:orange', label='');
axes.legend();
axes.text(train['timestamp'].iloc[9000000], -5, 'Train', fontsize=16);
axes.text(test['timestamp'].iloc[29400000], 16, 'Test', fontsize=16);
axes.axvspan(test['timestamp'].min(), test['timestamp'].max(), facecolor='green', alpha=0.2);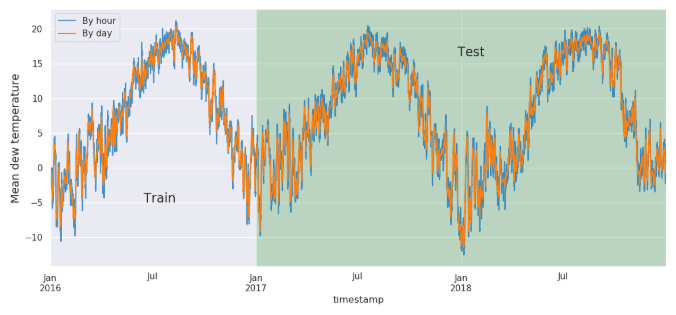
>> 2. 1位の解析手法
Pingback: kaggle1位の解析手法 「ASHRAE 消費エネルギー予測」2. 1位の解析手法 - S-Analysis