
![]()
![]()
![]()
![]()
関連記事:TensorFlow 2.0 主な変更点
今回の記事はTensorFlow モデル最適化ツールキットにあるPruning APIを解説と実験を行います。
目次
1. ニューラルネットワークのプルーニングとは
___1.1 プルーニングの概要
___1.2 TensorFlow モデル最適化ツールキット — Pruning API
2. 実験
___2.1 環境構築
___2.2 データのロード
___2.3 NNモデル
___2.4 プルーニングモデル
___2.5 モデルの評価
___2.6 TensorFlow Liteでモデル圧縮
3. まとめ
1. ニューラルネットワークのプルーニング(枝刈り)とは
1.1 プルーニングの概要
ニューラルネットワークのプルーニングとは、機械学習アルゴリズムを最適化する方法の一つとして、ニューラル ネットワークのレイヤー間のつながり(パラメーター)を削除することです。これにより、パラメーターの数を減らして計算を高速化します。
実際には、ニューラル ネットワークのパラメーターの値をゼロにすることで、ニューラル ネットワークのレイヤー間の不要なつながりと見なしたものを削除します。この処理はトレーニング プロセスで行います。繋がりを消すもの以外に、重みを0にすることでプルーニング(枝刈り)とも言います。
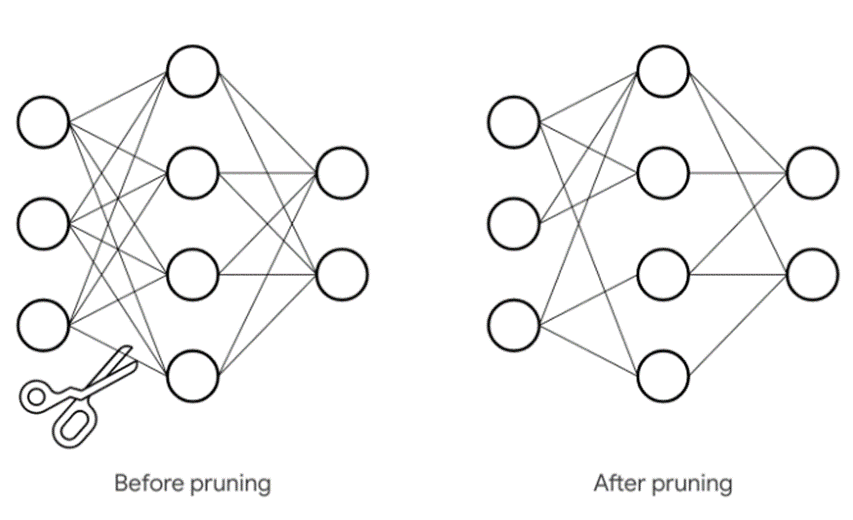
1.2 TensorFlow モデル最適化ツールキット — Pruning API
重みのプルーニングを行う API は、Keras をベースに構築されています。そのため、このテクニックはどんな既存の Keras トレーニング プログラムにも、とても簡単に適用できます。すなわちTensorflow2.xに対応しています。詳しいTensorflow2系については、過去記事をご覧ください。
プルーニング(枝刈り)のメリット
– 容量の圧縮
– モデルの格納サイズや転送サイズを減らすことができます。(TensorFlow Lite)
– プルーニングは量子化とも互換性があり、両方のメリットが得られることもわかっています
– TensorFlow Lite に疎表現と疎計算のファーストクラス サポートを追加して圧縮のメリットを実行時メモリにも拡大し、パフォーマンスの改善ができます。
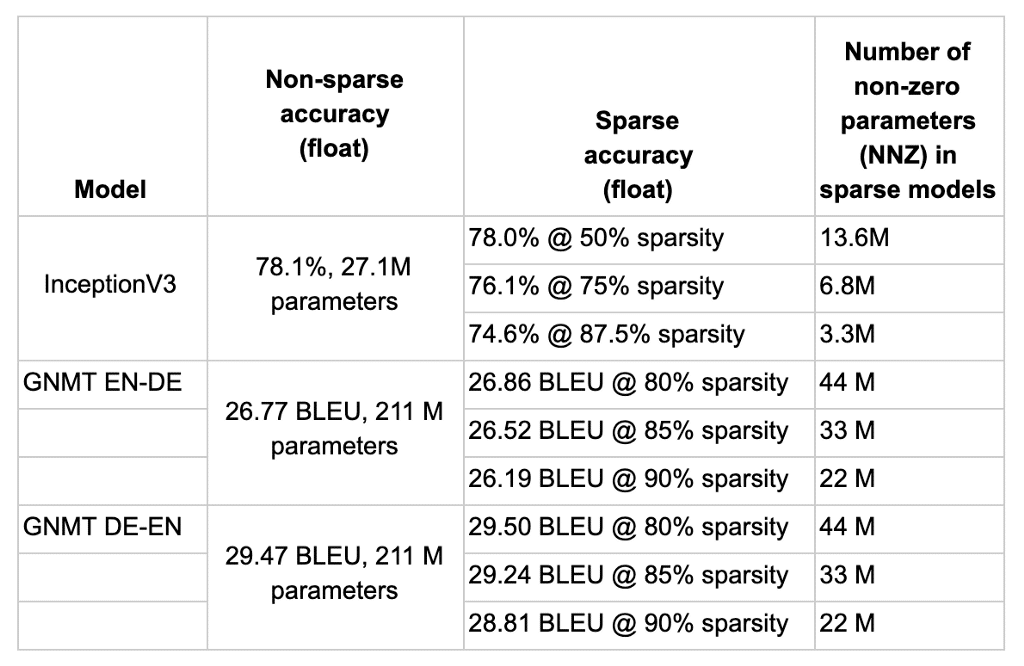
実験結果
イメージ処理用の畳み込みベースのニューラル ネットワークから再帰型ニューラル ネットワークを使う音声処理まで、さまざまなタスクで実験の結果です。
2. 実験
下記の実験を行います。
環境:Google Colab
データセット:MNIST:手書き数字の画像データセット
モデル:Kerasのニューラルネットワーク、ニューラルネットワークプルーニング
評価:Accuracy
2.1 環境構築
ライブラリのインストール
! pip install -q tensorflow-model-optimization
ライブラリのインポート
import tempfile
import os
import numpy as np
import pandas as pd
from datetime import datetime
import matplotlib.pyplot as plt
import random
import tensorflow as tf
from tensorflow import keras
from keras.datasets import mnist
result = {}モデルを保存するフォルダー作成
output_dir = ('temp/')
if not os.path.exists(output_dir):
os.makedirs(output_dir)2.2 データのロード
Kerasのデータセットを読み込んで 0-1に正規化します。
# Load MNIST dataset
mnist = keras.datasets.mnist
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
# 画像の表示
plt.rcParams['figure.figsize'] = (9,9) # Make the figures a bit bigger
for i in range(9):
plt.subplot(3,3,i+1)
num = random.randint(0, len(train_images))
plt.imshow(train_images[num], cmap='gray', interpolation='none')
plt.title("Class {}".format(train_labels[num]))
plt.tight_layout()
# 正規化
train_images = train_images / 255.0
test_images = test_images / 255.0
2.3 NNモデル
# MNIST without pruning
start_time = datetime.now()
# モデル構成
model = keras.Sequential([
keras.layers.InputLayer(input_shape=(28, 28)),
keras.layers.Reshape(target_shape=(28, 28, 1)),
keras.layers.Conv2D(filters=12, kernel_size=(3, 3), activation=tf.nn.relu),
keras.layers.MaxPooling2D(pool_size=(2, 2)),
keras.layers.Flatten(),
keras.layers.Dense(10)
])
# モデル設定
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
model.summary()
# モデル学習
model.fit(train_images, train_labels, epochs=4, validation_split=0.1)
# 結果
result[('1. NN no pruning', 'fit_time')] = datetime.now() - start_time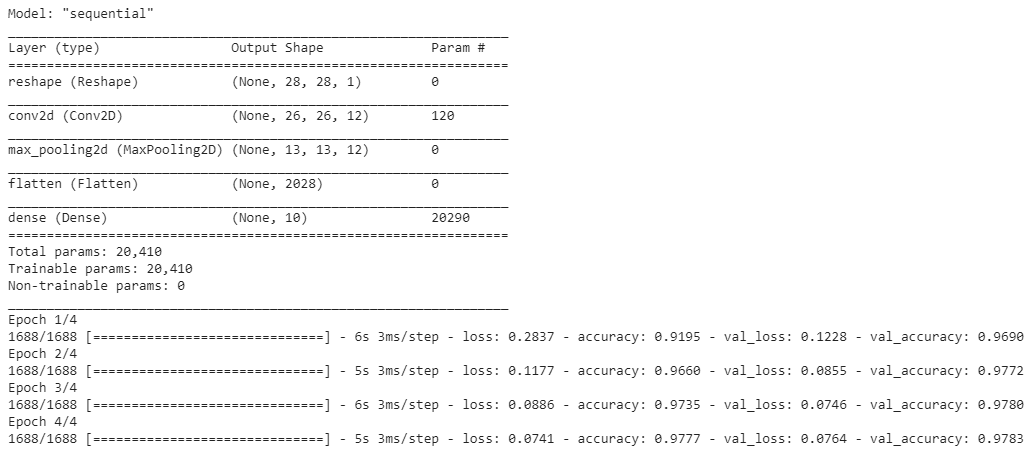
モデルを保存して、結果を表示します。枝刈り前は、精度が約97.5%でかつ計算時間は約36.6秒、モデルのファイルサイズは95KBであることがわかります。
# モデル保存
model_path = ('temp/model1.h5')
tf.keras.models.save_model(model, model_path, include_optimizer=False)
# 検証
_, baseline_model_accuracy = model.evaluate(test_images, test_labels, verbose=0)
result[('1. NN no pruning', 'accuracy')] = baseline_model_accuracy
result[('1. NN no pruning', 'file_size_KB')] = int(os.path.getsize(model_path)/ 1024)
# 結果表示
result_df = pd.Series(result).unstack().reindex(columns=['accuracy', 'fit_time', 'file_size_KB'])
result_df
2.4 プルーニングモデル
import tensorflow_model_optimization as tfmot
start_time = datetime.now()
prune_low_magnitude = tfmot.sparsity.keras.prune_low_magnitude
# 2 エポックでプルーニングモデルを作成
batch_size = 128
epochs = 2
validation_split = 0.1
num_images = train_images.shape[0] * (1 - validation_split)
end_step = np.ceil(num_images / batch_size).astype(np.int32) * epochs
# プルーニングの設定
pruning_params = {'pruning_schedule': tfmot.sparsity.keras.PolynomialDecay(initial_sparsity=0.50, final_sparsity=0.80, begin_step=0, end_step=end_step)}
model_for_pruning = prune_low_magnitude(model, **pruning_params)
# コンパイル
model_for_pruning.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
model_for_pruning.summary()
logdir = tempfile.mkdtemp()
callbacks = [
tfmot.sparsity.keras.UpdatePruningStep(),
tfmot.sparsity.keras.PruningSummaries(log_dir=logdir),
]
# モデル学習
model_for_pruning.fit(train_images, train_labels,
batch_size=batch_size, epochs=epochs, validation_split=validation_split,
callbacks=callbacks)
# 結果
result[('2. NN with pruning', 'fit_time')] = datetime.now() - start_time
2.5 モデルの評価
プルーニングのモデルは精度が少し減りましたが、学習時間は3倍くらい速くになりました。ところがモデルのファイルサイズは2倍になってしまいました。しかし軽量化を行うと大きく変わります。
# モデル保存
model_path = ('temp/model2.h5')
tf.keras.models.save_model(model_for_pruning, model_path, include_optimizer=False)
# 検証
_, model_for_pruning_accuracy = model_for_pruning.evaluate(test_images, test_labels, verbose=0)
result[('2. NN with pruning', 'accuracy')] = model_for_pruning_accuracy
result[('2. NN with pruning', 'file_size_KB')] = int(os.path.getsize(model_path)/ 1024)
# 結果表示
result_df = pd.Series(result).unstack().reindex(columns=['accuracy', 'fit_time', 'file_size_KB'])
result_df
2.6 TensorFlow Liteでモデル圧縮
TFliteを利用して、モデルの格納サイズや転送サイズを減らすことができます。
model_for_export = tfmot.sparsity.keras.strip_pruning(model_for_pruning)
converter = tf.lite.TFLiteConverter.from_keras_model(model_for_export)
pruned_tflite_model = converter.convert()
model_path = ('temp/model3.h5')
with open(model_path, 'wb') as f:
f.write(pruned_tflite_model)
result[('2. NN with pruning', 'TFLite_file_size_KB')] = int(os.path.getsize(model_path)/ 1024)
result_df = pd.Series(result).unstack().reindex(columns=['accuracy', 'fit_time', 'file_size_KB', 'TFLite_file_size_KB'])
result_df
3.まとめ
この実験では、TensorFlowとTFLiteの両方に対してTensorFlow Model Optimization Toolkit APIを使用してプルーニングを実験し、解説しました。プルーニングとトレーニング後の量子化を組み合わせて、追加の利点を得ます。
TFliteを利用して、モデルを圧縮しました。さらに、実行時メモリにも拡大し、パフォーマンスの改善ができました。精度は落ちていますが、過学習しているような際に有効な手法です。今回のmnistだと元が過学習していないので精度改善としてはいまいちな結果になっています。